进阶指南
1 - 服务配置
ProximaBE 设计时遵循最简配置原则,最大化降低用户启动成本,用户大部分场景直接使用默认配置文件即可。当然我们也开放了诸如日志、线程、网络端口等配置项,供用户根据自己场景配置。
1. 文件目录
ProximaBE 服务部署完之后,典型的文件结构如下:
proxima-be/
├── conf
│ └── proxima_be.conf
├── data
│ ├── plants
│ │ ├── data.del
│ │ ├── data.fwd.0
│ │ ├── data.id
│ │ ├── data.lsn
│ │ ├── data.manifest
│ │ └── data.pxa.image_vector.0
│ └── proxima_be.sqlite
└── log
├── proxima_be.log.ERROR -> proxima_be.log.ERROR.20210331-144121.10
├── proxima_be.log.INFO -> proxima_be.log.INFO.20210331-105941.10
├── proxima_be.log.WARNING -> proxima_be.log.WARNING.20210331-144121.10
├── proxima_be.log.ERROR.20210331-144121.10
├── proxima_be.log.INFO.20210331-105941.10
├── proxima_be.log.WARNING.20210331-144121.10
└── start.log
- conf目录,主要是服务静态配置,服务启动时会一次性加载生效
- data目录,主要是保存元数据以及集合数据
- log目录,保存日志数据,默认按2G大小切割
2. 配置项说明
配置项主要是指 proxima_be.conf 的结构,我们按主体功能将配置项分成4个部分:
- CommonConfig, 通用配置,包括网络端口、日志等配置项
- QueryConfig,查询配置,包括查询线程数配置项
- IndexConfig,写入配置,包括写入线程管理、限速等配置项
- MetaConfig, 元数据管理配置
proxima_be.conf 一份典型的默认配置如下,下面我们将详细介绍每个配置项的功能
common_config {
grpc_listen_port: 16000
http_listen_port: 16001
logger_type: "AppendLogger"
log_directory: "./log/"
log_file: "proxima_be.log"
log_level: 1
}
query_config {
query_thread_count: 8
}
index_config {
max_build_qps: 0
index_directory: "./"
flush_internal: 300
}
meta_config {
meta_uri: "sqlite:///proxima_be_meta.sqlite"
}
2.1 CommonConfig
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| grpc_listen_port | uint32 | 16000 | 否 | grpc协议监听端口 |
| http_listen_port | uint32 | 16001 | 否 | http协议监听端口 |
| logger_type | string | “AppendLogger” | 否 | 目前支持两种Logger AppendLogger–自动增加切割日志 SysLogger–打印到系统日志 |
| log_directory | string | “./log/” | 否 | 日志目录 |
| log_file | string | “proxima_be.log” | 否 | 日志名称 |
| log_level | uint32 | 2 | 否 | 最低打印日志级别 1–DEBUG 2–INFO 3–WARN 4–ERROR 5–FATAL |
2.2 QueryConfig
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| query_thread_count | uint32 | 8 | 否 | 查询的线程数据量,这里一般建议配置为 机器核数 ,写入和查询复用同一个线程池 |
2.3 IndexConfig
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| max_build_qps | uint32 | 0 | 否 | 写入限速,默认为0,代表不开限速功能 |
| index_directory | string | “./” | 否 | 索引目录,默认为当前目录 |
| flush_internal | uint32 | 300 | 否 | 内存数据定期同步间隔,单位为秒 |
2.4 MetaConfig
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| meta_uri | string | “sqlite://” | 否 | 元数据存储位置,默认为二进制当前目录 |
2 - 元数据
元数据用于描述集合的基本信息,其中主要包含的信息包含名称、属性列、索引列等信息,用户围绕集合元数据实现文档的增、删、改、查等功能。
1. 集合
集合用于描述一类数据,包含的数据描述如下表:
| 属性 | 描述 |
|---|---|
| 名称 | 集合名称,标识一个唯一的集合名 |
| 分片 | BE中对集合内的文档以主键排序后,按行进行分片,不同分片的两个文档具有存储不相关性,当在不同分片上的文档都会命中查询条件时,需要分别在两片数据中进行查询,并最终合并到一个返回结果中。 分片大小的配置对BE的性能影响较大,对查询性能较敏感的应用场景建议采用较大的分片大小配置。 特别提示: |
| 属性列 | 对于仅用于展示(不参与查询计算)的文档属性信息,可合并配置为文档属性列,BE内部会将属性列合并序列化后,集中存放在固定存储区,以达到更高的查询检索性能,更小的存储空间。特别提示: |
| 索引列 | 索引列用于标识文档的什么属性需要创建索引,被用于查询条件的列,均必须创建为索引。一个文档中可以有多个索引列,但不能指定某些索引是多种类型索引。具体索引列的说明见章节2 索引列 |
| 数据源 | BE中支持定义一个集合为Mysql源的镜像,在这种模式下会自动同步Mysql中的表至关联的集合中,具体使用请参考文章 TODO: Repository同步 |
2. 索引列
索引列是具有特定存储结构的列,用于加快用户的查询请求,目前BE中只开放了向量的图索引类型,索引列中需要包含的信息如下表:
| 属性 | 描述 |
|---|---|
| 列名 | 索引列名称,用户在检索中指定在某列中进行匹配查询 |
| 索引类型 | 目前只开放了向量图索引类型 |
| 数据类型 | 描述当前列中数据的类型,不同于传统的int8, int32,string等基础类型,向量类型一般会附加上vector前缀,比如说描述一个int8的向量,它对应的类型是vector_int8。 |
| 维度 | 描述数据所具有的维度空间(只有数据类型为向量时,此属性有效) |
| 高级属性 | 针对特定索引类型有效的高阶参数列表 |
3. 存储
3.1. 元数据存储
系统中元数据目前统一存储在Sqlite中,用户在生产环境中使用时请配置meta的存储路径为共享存储目录,详情参见高阶配置
3.2. 集合数据存储模式
BE属于列存储模式,相同列的数据紧凑存储,多列数据以行分片的模式相邻存储在同一文件内,集合文档的逻辑视图与存储视图如下表:
---
scale: 55
---
4. 元数据管理
BE中开放了元数据的管理API, 用户可通过BE API、SDK API进行元数据的管理工作,包含集合的增、删、改等功能
4.1. 使用BE API管理元数据
BE默认开放HTTP、GRPC两种协议API,HTTP API请参考文档RESTful HTTP, 对性能有需求的用户建议采用GRPC协议,接入方式可联系BE的开发团队接洽。
4.2. 使用SDK管理元数据
BE目前提供四种语言的SDK,请参考相关的SDK文档:
3 - 监控报警
ProximaBE 基于 brpc 的 bvar 功能,实现了兼容 Prometheus 的监控功能。
基本流程如下
- ProximaBE 配置使用 bvar 做监控。
- 配置 Prometheus,从 ProximaBE 订阅。
- 配置 Grafana,便于查询监控。
1. 配置 bvar
修改 proxima_be.conf,设置 common_config.metrics_config.name 为 bvar。
common_config {
# ...
metrics_config {
name: "bvar"
}
# ...
}
2. 配置 Prometheus
在 prometheus.yml 中的 scrape_configs 中,加入如下配置
- job_name: 'proxima-be'
# metrics_path defaults to '/metrics'
metrics_path: '/brpc_metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:16000']
完整的 prometheus.yml 可以从这里下载。
然后启动 prometheus(下载地址)
$ ./prometheus --config.file=prometheus.yml
3. 配置Grafana
- 启动并配置 Grafana
docker run -i -p 3000:3000 grafana/grafana - 在浏览器中打开 Grafana(地址如 http://localhost:3000/),并登录Grafana用户交互页面。
- 添加 Prometheus 数据源,参考官方文档
- 下载 Grafana配置文件,参考官方文档导入 Grafana。

4 - Repository
1. 基本概念
Repository 主要对数据源进行抽象。对于需要用于构建索引的数据可能存储在不同的存储系统中,比如 MySQL 数据库、Postgres 数据库和文件等等。为了支持从不同的存储系统中获取数据并把数据传送到 ProximaBE 用于后续的索引构建,我们提出了 Repository 的概念。 Repository 能够对接不同的存储系统,根据不同的存储系统实现相关的数据同步逻辑,并把数据的增、删、改等变化同步给 ProximaBE,从而使得相应的索引发生相应的变化。如下图所示:
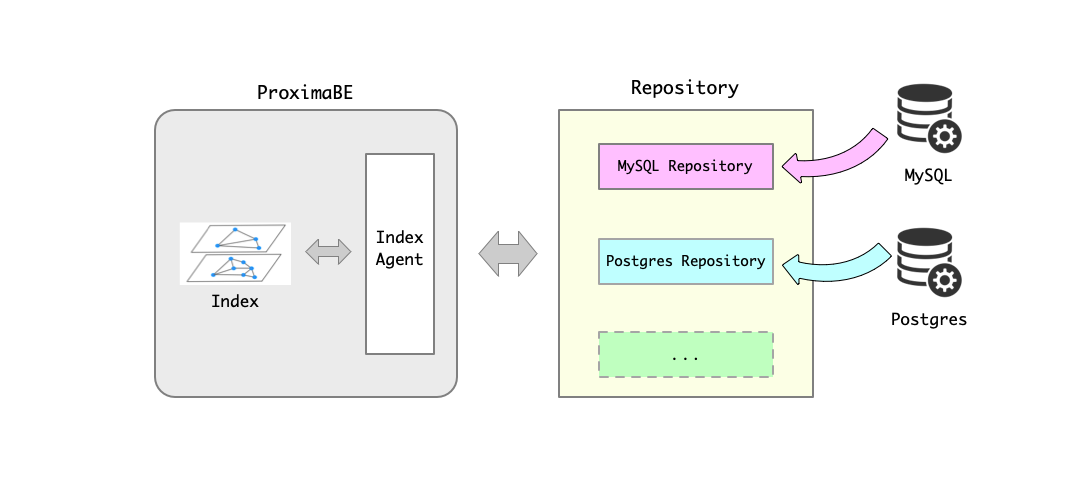
Repository 模块使得检索服务和原始数据的存储服务分离。从而拓展了 ProximaBE 的应用场景,增强了系统的可拓展性。当需要支持新的存储系统时,仅需实现相应的 Repository ,而不会影响 ProximaBE 的检索服务。
2. Repository 类型
按照设计每种存储系统对应一个相应的 Repository。例如,对于 MySQL 数据库对应的为 MySQL Repository,对于 Postgres 数据库对应 Postgres Repository 等等。 当前版本中仅支持 MySQL Repository,后续根据需要会添加 Postgres Repository 等更多的 Repository。
3. MySQL Repository
3.1. 基本概念
MySQL Repository 对接的数据源为 MySQL 数据库。MySQL Repository 利用 MySQL 的主从复制原理实现对 MySQL 数据库的实时订阅。
MySQL 的主从复制原理如下图所示:
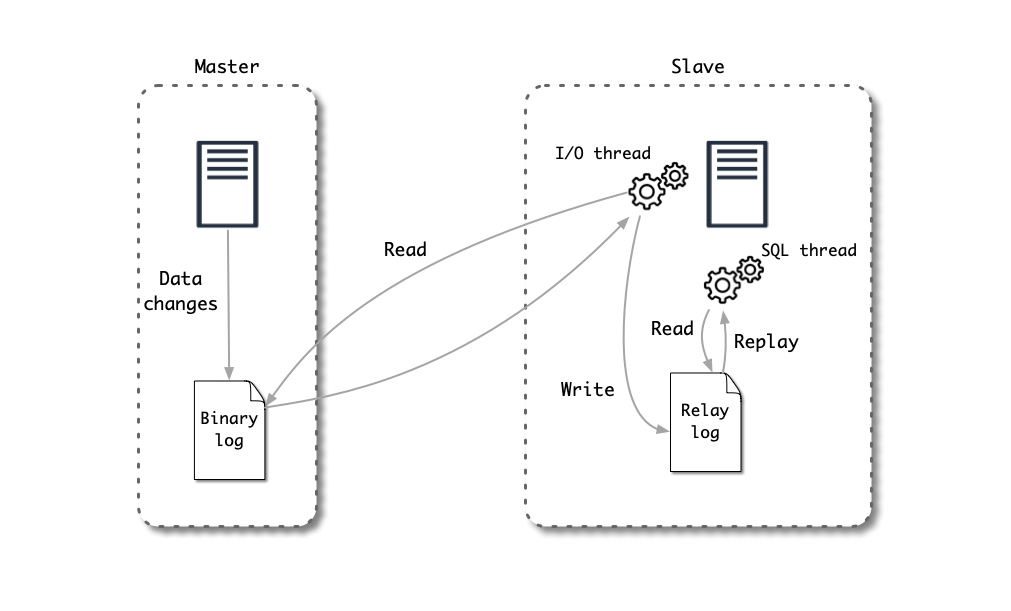
- MySQL 主服务器 (master) 将数据变更写入二进制日志( binary log)
- MySQL 从服务器 (slave) 将主服务器的 binary log 中的事件(event) 拷贝到它的中继日志(relay log)
- MySQL 从服务器重放中继日志中的事件,将数据变更反映它自己的数据中
MySQL Repository 的工作原理:
- MySQL Repository 模拟 MySQL Replica 原理,把自己伪装为 MySQL 从服务器,向 MySQL 主服务器发送 dump 请求
- MySQL 主服务器收到 dump 请求,开始推送 binlog 给 MySQL Repository
- MySQL Repository 解析相应的 binlog,解析为 ProximaBE 所需要的数据格式后发送给 ProximaBE
- ProximaBE 中的 Index Agent 模块接收到数据,并把数据传送给后续的索引构建模块
3.2. 快速开始
第一步: MySQL 基本设置
为了保证能够通过 binlog 正确获取 MySQL 数据库中数据,数据库和数据需要符合特定的设置:
- MySQL 版本 5.7.x
- 开启 binlog
- binlog 记录模式为 ROW 模式
- 表结构中含有自增列
MySQL 可以在文件 my.cnf 文件中进行设置。示例如下代码所示:
[mysqld]
server-id = 12000
log_bin = binlog
binlog_format = ROW
以 Docker 启动 MySQL:
$ docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
第二步: 拉取 MySQL Repository 镜像
安装前提见快速入门部分。这里不再赘述。
拉取 MySQL Repository Docker 镜像:
$ sudo docker pull ghcr.io/proximabilin/proxima-be
第三步: MySQL Repository 配置
创建配置文件、log 文件、数据文件所存储的路径:
$ mkdir -p $HOME/proxima-be/{conf,data,log}
首先需要启动 ProximaBE ,启动方式可以参照快速入门所述,这里不再赘述。在本示例中,假设 ProximaBE 和 MySQL Repository 在同一台机器且 ProximaBE 的 grpc_listen_port 为 16000。则 MySQL Repository 相应的配置文件可以如下所示: ( 位置:$HOME/proxima-be/conf/mysql_repo.conf):
common_config {
log_directory: "/var/lib/proxima-be/log/"
log_file: "mysql_repo.log"
}
repository_config {
index_agent_addr: "127.0.0.1:16000"
}
NOTE : 以上配置中 index_agent_addr 和 ProximaBE 的配置有关。表示 ProximaBE 的 IP 地址和 ProximaBE 的grpc_listen_port 值。
第四步: 映射文件启动容器
$ sudo docker run -d --name mysql-repository \
-v $HOME/proxima-be/conf:/var/lib/proxima-be/conf \
-v $HOME/proxima-be/data:/var/lib/proxima-be/data \
-v $HOME/proxima-be/log:/var/lib/proxima-be/log \
ghcr.io/proximabilin/proxima-be \
/var/lib/proxima-be/bin/mysql_repository --config /var/lib/proxima-be/conf/mysql_repo.conf
3.3. 详细配置
Common Config:
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| logger_type | string | “RepositoryAppendLogger” | 否 | 目前支持一种Logger RepositoryAppendLogger–自动增加切割日志 |
| log_directory | string | “./log/” | 否 | 日志目录 |
| log_file | string | “mysql_repository.log” | 否 | 日志名称 |
| log_level | uint32 | 2 | 否 | 最低打印日志级别 1–DEBUG 2–INFO 3–WARN 4–ERROR 5–FATAL |
Repository Config:
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| index_agent_addr | string | “0.0.0.0:16000” | 是 | index agent IP 地址和端口号 |
| repository_name | string | “mysql_repository” | 否 | repository 名字 |
| load_balance | string | "" | 否 | RPC 负载均衡 |
| batch_size | uint32 | 64 | 否 | Repository 向 ProximaBE 传送数据的最大 batch 大小 |
| batch_interval | uint32 | 5000 | 否 | Repository 向 ProximaBE 传送数据的最大时间间隔。单位“微妙” |
| max_retry | int | 3 | 否 | RPC 重试次数 |
| timeout_ms | int | 500 | 否 | RPC 超时时间,单位“毫秒” |
3.4. MySQL 表配置说明
想要要通过 MySQL Repository 的方式来自动进行数据同步,需要满足下面几点:
- 用户定义的 MySQL 表中必须含有一个自增列 ID。
- 在集合中定义的向量索引字段,在 MySQL 表中对应的字段必须是 VARCHAR 类型,格式为 Json Array 的字符串,其它格式的暂时不支持,例如:
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0] - 在集合中定义的向量正排字段,可以是 MySQL 中支持的常规类型,目前 geometry 和 json 等复杂类型暂时不支持配置。
示例:
# 1、创建MySQL表
CREATE TABLE `test_table` (
`id` int(11) NOT NULL AUTO_INCREMENT, # 自增列 ID
`name` varchar(64) NOT NULL, # 姓名
`age` int(11) NOT NULL, # 年龄
`score` float NOT NULL, # 信用分
`face` varchar(10240) NOT NULL, # 人脸向量,假定为4维的float
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 2、插入数据
insert into test_table(name, age, score, face) values ('xiaoming', 23, 95.3, '[1.0, 2.0, 3.0, 4.0]');
insert into test_table(name, age, score, face) values ('xiaohua', 24, 85.3, '[2.5, 3.0, 3.5, 4.5]');
# 3、创建集合的配置
# face -> 向量索引列(IndexColumn)
# id, name, age, score -> 正排列(ForwardColumn)
5 - 性能调优
6 - 常用工具
在 Proxima BE 发布的镜像中,附带了几个常用工具,主要是方便客户管理 collection 和文档。
1. 如何获取
相关工具位于镜像 ghcr.io/proximabilin/proxima-be 的目录 /var/lib/proxima-be/bin/
2. admin_client
2.1 使用方法
$ admin_client -h
Usage:
admin_client <args>
Args:
--command Command type: create | drop
--host The host of proxima be, http port
--collection Specify collection name
--schema Specify collection schema format
--help, -h Display help info
--version, -v Dipslay version info
2.2 创建Collection
$ admin_client --command create --host 127.0.0.1:16001 --collection test_collection \
--schema '{"collection_name":"test_collection", "index_column_params":[{"column_name":"test_column",
"index_type": "IT_PROXIMA_GRAPH_INDEX", "data_type":"DT_VECTOR_FP32", "dimension":8}]}'
2.3 删除Collection
$ admin_client --command drop --host 127.0.0.1:16001 --collection test_collection
3. bench_client
3.1 使用方法
$ bench_client -h
Usage:
bench_client <args>
Args:
--command Command type: search|insert|delete|update
--host The host of proxima be
--collection Specify collection name
--column Specify column name
--file Read input data from file
--protocol Protocol http or grpc
--concurrency Send concurrency (default 10)
--topk Topk results (default 10)
--perf Output perf result (default false)
--help, -h Display help info
--version, -v Display version info
3.2 插入数据
$ bench_client --command insert --host 127.0.0.1:16000 --collection test_collection --column test_column --file
data.txt
数据格式支持明文和二进制两种,key与向量之间用";“分隔,多维向量采用空间分割,样例数据如下:
0;-0.009256 -0.079674 -0.070349 0.007072 -0.064061 -0.010632 0.083429 -0.074821
1;-0.061519 -0.001263 -0.016528 0.031539 0.041385 -0.017736 -0.005704 0.129443
2;-0.039616 -0.063191 0.057591 -0.090278 -0.007452 -0.035939 -0.021892 -0.037860
3;0.042097 0.050037 0.055060 0.150511 -0.052841 -0.005502 -0.018618 0.054607
3.3 查询数据
query数据格式同上述的插入数据格式相同。
$ bench_client --command search --host 127.0.0.1:16000 --collection test_collection --column test_column --file
query.txt
3.4 删除数据
data数据格式同上述的插入数据格式相同。
$ bench_client --command delete --host 127.0.0.1:16000 --collection test_collection --column test_column --file
data.txt
4. index_builder
对于数据集已经提前准备好的场景,为加速索引构建,可通过离线构建工具加速构建。
4.1 使用方法
Usage:
index_builder <args>
Args:
--schema Specify the schema of collection
--file Specify input data file
--output Sepecify output index directory(default ./)
--concurrency Sepecify threads count for building index(default 10)
--help, -h Dipslay help info
--version, -v Dipslay version info
4.2 数据文件格式说明
每行一条记录,由 ‘;’ 分隔。分别是 key,向量,正排属性。其中 key 为 uint64 类型,向量各维度用 ' ' 分隔。属性可选。例如
111;1.0 1.1 1.2 1.3;a,b
4.3 使用示例
test.txt 内容为上述内容的文件。则构建索引可用如下命令:
index_builder --output index --schema '{"collection_name":"test_collection", "forward_column_names":["k1"], "index_column_params":[{"column_name":"test_column",
"index_type": "IT_PROXIMA_GRAPH_INDEX", "data_type":"DT_VECTOR_FP32", "dimension":4}]}' --file test.txt
4.3 使用注意
由于离线工具构建的索引没有相应 meta 信息。如果作为 Proxima SE 提供检索能力。需要创建一个对应的 collection。 例如启动 proxima_se 服务时,配置好相应的索引位置为 index:
common_config {
grpc_listen_port: 16000
http_listen_port: 16001
}
index_config {
index_directory: "index/"
}
query_config {
query_thread_count: 8
}
启动后,使用如下命令创建相应集合。
curl -X POST http://0.0.0.0:16001/v1/collection/test_collection -d '{"collection_name":"test_collection", "forward_column_names":["k1"], "index_column_params":[{"column_name":"test_column","index_type": "IT_PROXIMA_GRAPH_INDEX", "data_type":"DT_VECTOR_FP32", "dimension":4}]}'
然后进行检索
curl -X POST \
http://0.0.0.0:16001/v1/collection/test_collection/query \
-d '{
"knn_param":{
"column_name":"test_column",
"topk":10,
"matrix":"[[1.0, 2.0, 3.0, 4.0]]",
"batch_count":1,
"dimension":4,
"data_type":"DT_VECTOR_FP32",
"is_linear":true,
}
}'
# 返回
{"status":{"code":0,"reason":"Success"},"results":[{"documents":[{"score":11.34,"primary_key":"111","forward_column_values":[{"key":"k1","value":{"string_value":"a,b"}}]}]}],"debug_info":"","latency_us":"902"}