文档
- 1: 简介
- 2: 快速开始
- 3: 进阶指南
- 4: API 手册
- 4.1: REST APIs
- 5: SDK 手册
- 5.1: Python SDK
- 5.2: C++ SDK
- 5.3: Java SDK
- 5.4: Golang SDK
- 6: 案例教程
- 6.1: 图片搜索
- 7: 常见问题
- 8: 发行版本
- 9: 性能测试
- 9.1: 性能测试
1 - 简介
随着 AI 技术的广泛应用,以及数据规模的不断增长,向量检索也逐渐成了 AI 技术链路中不可或缺的一环,不仅实现了对传统搜索技术的补充,还具备多模态搜索的能力。
Proxima 是阿里巴巴达摩院系统 AI 实验室自研的向量检索内核。目前,其核心能力广泛应用于阿里巴巴和蚂蚁集团内众多业务,如淘宝搜索和推荐、蚂蚁人脸支付、优酷视频搜索、阿里妈妈广告检索等。同时,Proxima 还深度集成在各式各类的大数据和数据库产品中,如阿里云 Hologres、搜索引擎 Elastic Search 和 ZSearch、离线引擎 MaxCompute (ODPS) 等,为其提供向量检索的能力。
ProximaBE,全称 Proxima Bilin Engine,是 Proxima 团队开发的服务化引擎,实现了对大数据的高性能相似性搜索,支持流式 CRUD,支持 RESTful API,支持 GPRC 协议,支持数据库全量和增量同步。
设计架构
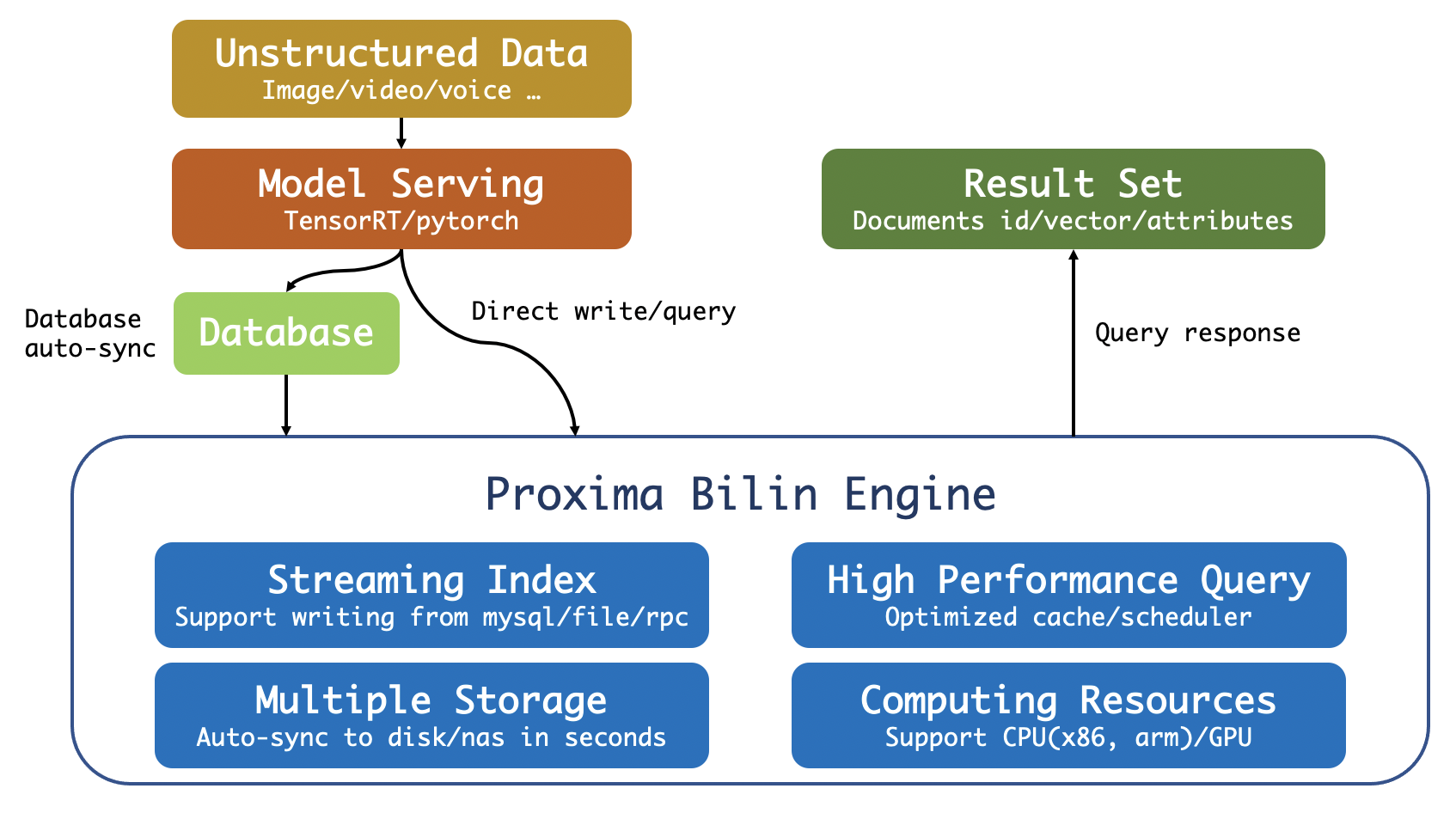
ProximaBE 定位为数据旁路的云原生向量检索服务引擎,其角色为计算节点或缓存服务,同时也支持独立部署以及服务能力。核心功能点包括:
- 支持高性能实时向量增删查改;
- 支持多数据源全量和增量同步;
- 支持正排数据查询;
- 支持多表隔离和查询;
- 支持索引多分片查询;
基础概念
ProximaBE 中定义了集合(Collection),文档(Document), 索引(Index), 正排(Forward)等基础概念,以上概念与传统数据库概念对比可以参考下图:
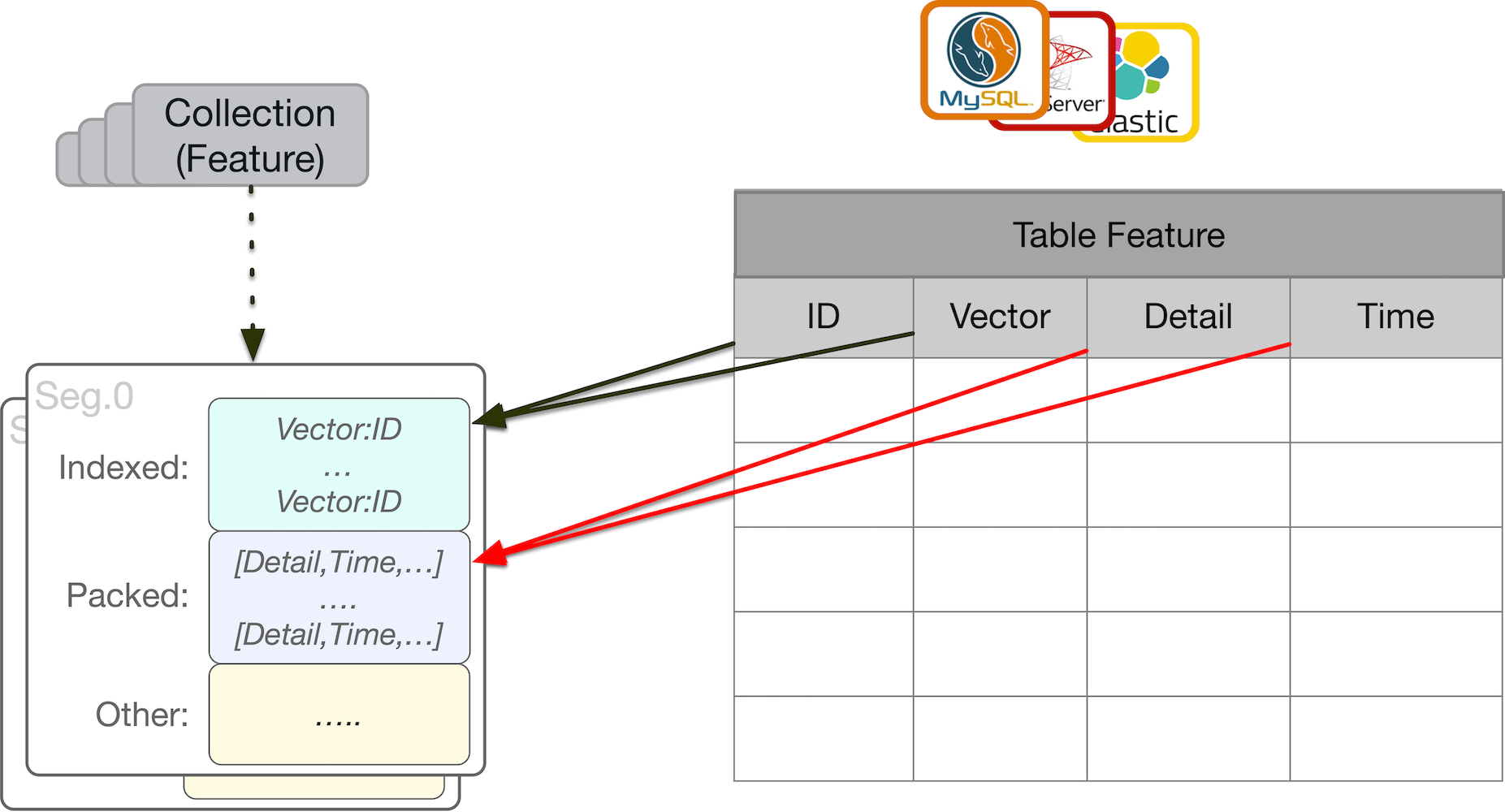
如上图所示, 集合与数据库中的 Table 是映射关系,索引(Index)映射数据库表中的某列数据,属性(Forward)映射为数据库表中的多列数据。
集合(Collection) : 集合用于描述用户具有相同数据结构的文档集合,它对应数据库中的表概念。
文档(Document) : 文档用于描述用户结构化数据,它包含基本的一些存储数据元,一个文档可包含多个索引列,以及属性列。
索引(Index) : 用于描述一个文档中需要被建立索引的列数据,该字段为查询接口的主要计算单元,用户加快计算过程。
正排(Forward) : 只存储需要与文档关联的一些属性列,该字段不参与查询时的逻辑计算,只用于数据展示。文档中可包含多个属性列,并且存储时多字段合并后压缩存储。
名词解释
| 名词 | 解释 |
|---|---|
| 向量检索 | 向量是一种将实体代数化的表示,如同数学空间中的坐标,标识着各个实体,其将实体间的关系抽象成向量空间中的距离,而距离的远近代表着相似程度。向量检索便是对这类结构化的数据进行快速搜索和匹配的方法。 |
| KNN | KNN,全称 K-Nearest Neighbor,查找离查询点最近的 K 个点。 |
| RNN | RNN,全称 Radius Nearest Neighbor,查找查询点某半径范围内的所有点或 K 个点。 |
| ANN | ANN,全称 Approximate Nearest Neighbor。在涉及到大数据量的情况下,百分之百准确求解 KNN 或 RNN 问题的计算成本较高,于是引入了求近似性解的方法,尽可能地或按概率的方式满足检索需求,因此大数据量检索实际要解决的是 ANN 的问题。 |
| KNN Graph | 一种索引方法,预先建立好向量之间的邻居关系,形成 Graph 的索引结构。检索时,通过在图上的游走遍历获取最终的 KNN 结果。 |
| 量化 | 量化,将连续值(或者大量的离散取值)近似为有限多个(或较少的)离散值的过程。例如,聚类便是一种量化方法。量化索引是指利用量化方法构建和检索的索引方法,特征量化则是指对向量特征本身进行数值变化。 |
2 - 快速开始
2.1 - 安装指南
ProximaBE 具备极简依赖、快速部署、多平台支持等特点。其目前支持主流的 RedHat 系列 Linux 发行版本,包括 RHEL、Centos、taobao7u 等,支持 x86/x64 和 aarch64 等体系架构。
1. Docker 镜像安装
1.1. 安装前提
我们推荐安装 1.12.6 以上版本 Docker。用户可以在安装镜像前确认自己的 Docker 版本以及状态
$ sudo docker info
1.2. 拉取Docker镜像
$ docker pull ghcr.io/proximabilin/proxima-be
1.3. 启动容器
1.3.1. 快速启动容器
使用容器内置的配置文件来启动服务,便于快速上手。但是容器销毁时数据也会丢失,生产环境部署请用映射文件启动的模式。
$ sudo docker run -d --name proxima_be -p 16000:16000 -p 16001:16001 \
ghcr.io/proximabilin/proxima-be
NOTE: 低版本 docker 需要在上述命令中增加
--net=host选项
1.3.2. 映射文件启动容器
通过将本机目录映射到容器,在容器删除时数据文件仍然可用。
- 创建相关目录,修改配置文件
$ mkdir -p $HOME/proxima-be/{conf,data,log}
$ vim /$HOME/proxima-be/conf/proxima_be.conf # 镜像中有默认配置 /var/lib/proxima-be/conf/proxima_be.conf
- 执行下面的命令启动容器
$ sudo docker run -d --name proxima_be -p 16000:16000 -p 16001:16001 \
-v $HOME/proxima-be/conf:/var/lib/proxima-be/conf \
-v $HOME/proxima-be/data:/var/lib/proxima-be/data \
-v $HOME/proxima-be/log:/var/lib/proxima-be/log \
ghcr.io/proximabilin/proxima-be
1.3.3. 其他容器操作
停止服务
$ docker stop proxima_be
WARNING: kill 容器或者强制删除容器有可能导致数据丢失,慎用下面的命令。
$ docker kill proxima_be $ docker rm -f proxima_be
2.2 - 使用样例
在上文安装指南中,我们详细介绍了 ProximaBE 的安装和启动方法, 接下来我们将使用一个样例来介绍 ProximaBE 的服务使用方法。 在样例程序中,我们将使用两种示例代码演示创建一个名为 “Plants” 的集合,并尝试插入一批数据,然后查询比对的过程。
1. Http 示例
示例中我们选用 curl 工具来演示 http 协议的访问 ProximaBE 过程,用户也可以使用其它的 http 发送工具来替代。
1.1. 创建Collection
下列示例脚本将创建一个名为 Plants 的集合,有一个名为 “ImageVector” 的向量索引列, 以及 “Price” 和 “Description” 两个正排列。
其中索引列的具体承载数据类型为 8 维 float 类型的向量,索引类型为向量图索引。
$ curl -X POST http://127.0.0.1:16001/v1/collection/Plants \
-d '{"collection_name":"Plants",
"forward_column_names":["Price", "Description"],
"index_column_params":[{
"column_name":"ImageVector",
"index_type":"IT_PROXIMA_GRAPH_INDEX",
"data_type":"DT_VECTOR_FP32",
"dimension": 8}]
}'
Exec output:
{"code":0,"reason":"Success"}
1.2 查看Collection
创建成功的集合,我们可以直接使用访问查看。
$ curl -X GET http://127.0.0.1:16001/v1/collection/Plants
Exec output:
{"status":{"code":0,"reason":"Success"},"collection":{"uuid":"8e5b79bbdc198cc2dccdde0710f86f45","config":
{"collection_name":"Plants","index_column_params":
[{"data_type":"DT_VECTOR_FP32","dimension":8,"index_type":"IT_PROXIMA_GRAPH_INDEX","column_name":"ImageVector","
extra_params":[]}],"forward_column_names":
["Price","Description"],"max_docs_per_segment":"18446744073709551615"},"status":"CS_SERVING","magic_number":"0"}
}
1.3. 写入文档
下面示例中向 Plants 集合插入了 2 条数据(受限于展示,用户可以自由扩展 rows 字段),注意rows中的字段值顺序应与 row_meta 中的描述保持一致。
$ curl -X POST http://127.0.0.1:16001/v1/collection/Plants/index \
-d '{"collection_name":"Plants",
"row_meta": {
"forward_column_names":["Price", "Description"],
"index_column_metas": [{
"column_name":"ImageVector",
"data_type":"DT_VECTOR_FP32",
"dimension":8}]
},
"rows":[
{
"primary_key":0,
"operation_type":"OP_INSERT",
"forward_column_values":{
"values":[{"float_value":0.1}, {"string_value":"ginkgo tree with number 0"}]},
"index_column_values":{
"values":[{"string_value":"[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]"}]}
},
{
"primary_key":1,
"operation_type":"OP_INSERT",
"forward_column_values":{
"values":[{"float_value":1.1}, {"string_value":"ginkgo tree with number 1"}]},
"index_column_values":{
"values":[{"string_value":"[1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8]"}]}
}
]
}'
Exec output:
{"code":0,"reason":"Success"}
1.4. 查询文档
下面示例代码中展示了我们Knn 查找top1图像的过程,结果应该准确命中第一条文档,用户可以自由设置topk。
$ curl -X POST http://127.0.0.1:16001/v1/collection/Plants/query \
-d '{"collection_name":"Plants",
"query_type":"QT_KNN",
"knn_param": {
"column_name":"ImageVector",
"topk":1,
"matrix": "[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]",
"batch_count":1,
"dimension":8,
"data_type":"DT_VECTOR_FP32"}
}'
Exec output:
{"status":{"code":0,"reason":"Success"},"results":[{"documents":
[{"score":0,"primary_key":"0","forward_column_values":[{"key":"Price","value":{"float_value":0.1}},
{"key":"Description","value":{"string_value":"ginkgo tree with number
0"}}]}]}],"debug_info":"","latency_us":"636"}
1.5 Collection统计
经过一段时间累积,我们希望能够获取某个集合的详细信息,则可以通过下列示例访问:
$ curl -X GET http://127.0.0.1:16001/v1/collection/Plants/stats
Exec output:
{"status":{"code":0,"reason":"Success"},"collection_stats":{"segment_stats":
[{"state":"SS_WRITING","max_lsn":"0","min_lsn":"0","doc_count":"2","max_doc_id":"1","min_doc_id":"0","segment_id
":0,"segment_path":"","max_timestamp":"0","min_timestamp":"0","index_file_size":"2142208","max_primary_key":"1",
"min_primary_key":"0","index_file_count":"2"}],"collection_name":"Plants","collection_path":"/home/x x x/c
ode/proxima-
se/build/test_dir/Plants","total_doc_count":"2","total_segment_count":"1","total_index_file_size":"22241280","to
tal_index_file_count":"6"}}
1.6 删除Collection
$ curl -X DELETE http://127.0.0.1:16001/v1/collection/Plants
Exec output:
{"code":0,"reason":"Success"}
2. Python 示例
2.1. Python SDK 安装
在安装python sdk之前请确保系统中已安装python3.6以及pip程序。
$ pip install -i https://pypi.antfin-inc.com/simple/ -U pyproximabe==0.1.2
2.2. 连接Client
在具体操作之前,我们需要创建client连接ProximaBE,当前支持http和grpc协议。Client默认为同步请求,同时我们也支持AsyncClient做异步请求。参考代码如下:
from pyproximabe import *
# Init client
client = Client('127.0.0.1', 16000)
2.3. 创建Collection
在下列代码中,我们创建了一个名为Plants的集合。其中一个索引列名为"ImageVector",顾名思义主要是存放图片向量,以及"Price"和"Description"两个正排列。
创建Collection的参数主要是需要描述索引列的结构,比如索引类型、数据类型、维度等信息。 正排列则仅描述列名即可。
# Init index column
index_column = IndexColumnParam(name='ImageVector',
dimension=8,
data_type=DataType.VECTOR_FP32,
index_type=IndexType.PROXIMA_GRAPH_INDEX)
# Init collection config
collection_config = CollectionConfig('Plants',
index_column_params=[index_column],
max_docs_per_segment=0,
forward_column_names=['Price','Description'])
# Create collection
status = client.create_collection(collection_config)
# Check Return
print(status)
Exec output:
success
2.3 查看Collection
# Get collection info
status = client.describe_collection('Plants')
print(status)
Exec output:
(<pyproximabe.core.types.ProximaBeStatus object at 0x7f63b0a41ac8>, CollectionInfo{'collection_config':
CollectionConfig{'collection_name': 'Plants', 'index_column_params': [IndexColumnParam{'name': 'ImageVector',
'dimension': 8, 'index_type': <IndexType.PROXIMA_GRAPH_INDEX: 1>, 'data_type': <DataType.VECTOR_FP32: 23>,
'extra_params': {}}], 'max_docs_per_segment': 18446744073709551615, 'forward_column_names': ['Price',
'Description'], 'repository_config': None}, 'status': <Status.SERVING: 1>, 'uuid':
'dbd57611e812164b7e7b697ea0af684c', 'latest_lsn_context': LsnContext{'lsn': 0, 'context': ''}, 'magic_number':
0})
2.4. 写入文档
名为"plants"的Collection创建完成之后,我们向其中写入100条文档。
发送数据前,我们需要描述发送的数据格式RowMeta,主要供后端校验使用。至于写入模式分两种,可以支持批量,也可以支持单条发送,而写入请求类型支持OperationType.INSERT,OperationType.DELETE,OperationType.UPDATE 三种。
# Set record data format
index_column_meta = WriteRequest.IndexColumnMeta(name='ImageVector',
data_type=DataType.VECTOR_FP32,
dimension=8)
row_meta = WriteRequest.RowMeta(index_column_metas=[index_column_meta],
forward_column_names=['Price','Description'],
forward_column_types=[DataType.FLOAT, DataType.STRING])
# Send 100 records
rows = []
for i in range(0, 100):
vector = [i+0.1, i+0.2, i+0.3, i+0.4, i+0.5, i+0.6, i+0.7, i+0.8]
price = i + 0.1
description = "ginkgo tree with number " + str(i)
row = WriteRequest.Row(primary_key=i,
operation_type=WriteRequest.OperationType.INSERT,
index_column_values=[vector],
forward_column_values=[price, description])
rows.append(row)
write_request = WriteRequest(collection_name='Plants',
rows=rows,
row_meta = row_meta)
status = client.write(write_request)
print(status)
Exec Output:
success
2.5. 查询文档
插入完100条文档到Plants之后,我们挑选5条查询看看,是否能够准确返回对应的图片。
# Query
query_vector = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]
status, knn_res = client.query(collection_name='Plants',
column_name='ImageVector',
features=query_vector,
data_type=DataType.VECTOR_FP32,
topk = 5)
print(status)
print(knn_res)
Exec ouput:
success
QueryResponse{'results': [[Document{'primary_key': 0, 'score': 0.0, 'forward_column_values': {'Price':
0.10000000149011612, 'Description': 'ginkgo tree with number 0'}}, Document{'primary_key': 1, 'score': 8.0,
'forward_column_values': {'Price': 1.100000023841858, 'Description': 'ginkgo tree with number 1'}},
Document{'primary_key': 2, 'score': 32.0, 'forward_column_values': {'Price': 2.0999999046325684, 'Description':
'ginkgo tree with number 2'}}, Document{'primary_key': 3, 'score': 72.0, 'forward_column_values': {'Price':
3.0999999046325684, 'Description': 'ginkgo tree with number 3'}}, Document{'primary_key': 4, 'score': 128.0,
'forward_column_values': {'Price': 4.099999904632568, 'Description': 'ginkgo tree with number 4'}}]],
'debug_info': '', 'latency_us': 269}
2.6. Collection统计
我们也可以通过统计接口查看Collection的内部数据和状态。
# Get collection statistics
status, collection_stats = client.stats_collection('Plants')
print(status)
print(collection_stats)
Exec ouput:
success
CollectionStats{'collection_name': 'Plants', 'collection_path': '/home/xxx/code/proxima-
be/build/test_dir/Plants', 'total_doc_count': 100, 'total_segment_count': 1, 'total_index_file_count': 6,
'total_index_file_size': 22241280, 'segment_stats': [SegmentStats{'segment_id': 0, 'state':
<SegmentState.WRITING: 1>, 'doc_count': 100, 'index_file_count': 2, 'index_file_size': 2142208, 'min_doc_id': 0,
'max_doc_id': 99, 'min_primary_key': 0, 'max_primary_key': 99, 'min_timestamp': 0, 'max_timestamp': 0, 'min_lsn': 0, 'max_lsn': 0, 'segment_path': ''}]}
2.7. 删除Collection
实验完关于"plants"的一切之后,我们希望能够删除Collection。
# Drop collection
status = client.drop_collection('Plants')
print(status)
Exec output:
success
3 - 进阶指南
3.1 - 服务配置
ProximaBE 设计时遵循最简配置原则,最大化降低用户启动成本,用户大部分场景直接使用默认配置文件即可。当然我们也开放了诸如日志、线程、网络端口等配置项,供用户根据自己场景配置。
1. 文件目录
ProximaBE 服务部署完之后,典型的文件结构如下:
proxima-be/
├── conf
│ └── proxima_be.conf
├── data
│ ├── plants
│ │ ├── data.del
│ │ ├── data.fwd.0
│ │ ├── data.id
│ │ ├── data.lsn
│ │ ├── data.manifest
│ │ └── data.pxa.image_vector.0
│ └── proxima_be.sqlite
└── log
├── proxima_be.log.ERROR -> proxima_be.log.ERROR.20210331-144121.10
├── proxima_be.log.INFO -> proxima_be.log.INFO.20210331-105941.10
├── proxima_be.log.WARNING -> proxima_be.log.WARNING.20210331-144121.10
├── proxima_be.log.ERROR.20210331-144121.10
├── proxima_be.log.INFO.20210331-105941.10
├── proxima_be.log.WARNING.20210331-144121.10
└── start.log
- conf目录,主要是服务静态配置,服务启动时会一次性加载生效
- data目录,主要是保存元数据以及集合数据
- log目录,保存日志数据,默认按2G大小切割
2. 配置项说明
配置项主要是指 proxima_be.conf 的结构,我们按主体功能将配置项分成4个部分:
- CommonConfig, 通用配置,包括网络端口、日志等配置项
- QueryConfig,查询配置,包括查询线程数配置项
- IndexConfig,写入配置,包括写入线程管理、限速等配置项
- MetaConfig, 元数据管理配置
proxima_be.conf 一份典型的默认配置如下,下面我们将详细介绍每个配置项的功能
common_config {
grpc_listen_port: 16000
http_listen_port: 16001
logger_type: "AppendLogger"
log_directory: "./log/"
log_file: "proxima_be.log"
log_level: 1
}
query_config {
query_thread_count: 8
}
index_config {
max_build_qps: 0
index_directory: "./"
flush_internal: 300
}
meta_config {
meta_uri: "sqlite:///proxima_be_meta.sqlite"
}
2.1 CommonConfig
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| grpc_listen_port | uint32 | 16000 | 否 | grpc协议监听端口 |
| http_listen_port | uint32 | 16001 | 否 | http协议监听端口 |
| logger_type | string | “AppendLogger” | 否 | 目前支持两种Logger AppendLogger–自动增加切割日志 SysLogger–打印到系统日志 |
| log_directory | string | “./log/” | 否 | 日志目录 |
| log_file | string | “proxima_be.log” | 否 | 日志名称 |
| log_level | uint32 | 2 | 否 | 最低打印日志级别 1–DEBUG 2–INFO 3–WARN 4–ERROR 5–FATAL |
2.2 QueryConfig
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| query_thread_count | uint32 | 8 | 否 | 查询的线程数据量,这里一般建议配置为 机器核数 ,写入和查询复用同一个线程池 |
2.3 IndexConfig
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| max_build_qps | uint32 | 0 | 否 | 写入限速,默认为0,代表不开限速功能 |
| index_directory | string | “./” | 否 | 索引目录,默认为当前目录 |
| flush_internal | uint32 | 300 | 否 | 内存数据定期同步间隔,单位为秒 |
2.4 MetaConfig
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| meta_uri | string | “sqlite://” | 否 | 元数据存储位置,默认为二进制当前目录 |
3.2 - 元数据
元数据用于描述集合的基本信息,其中主要包含的信息包含名称、属性列、索引列等信息,用户围绕集合元数据实现文档的增、删、改、查等功能。
1. 集合
集合用于描述一类数据,包含的数据描述如下表:
| 属性 | 描述 |
|---|---|
| 名称 | 集合名称,标识一个唯一的集合名 |
| 分片 | BE中对集合内的文档以主键排序后,按行进行分片,不同分片的两个文档具有存储不相关性,当在不同分片上的文档都会命中查询条件时,需要分别在两片数据中进行查询,并最终合并到一个返回结果中。 分片大小的配置对BE的性能影响较大,对查询性能较敏感的应用场景建议采用较大的分片大小配置。 特别提示: |
| 属性列 | 对于仅用于展示(不参与查询计算)的文档属性信息,可合并配置为文档属性列,BE内部会将属性列合并序列化后,集中存放在固定存储区,以达到更高的查询检索性能,更小的存储空间。特别提示: |
| 索引列 | 索引列用于标识文档的什么属性需要创建索引,被用于查询条件的列,均必须创建为索引。一个文档中可以有多个索引列,但不能指定某些索引是多种类型索引。具体索引列的说明见章节2 索引列 |
| 数据源 | BE中支持定义一个集合为Mysql源的镜像,在这种模式下会自动同步Mysql中的表至关联的集合中,具体使用请参考文章 TODO: Repository同步 |
2. 索引列
索引列是具有特定存储结构的列,用于加快用户的查询请求,目前BE中只开放了向量的图索引类型,索引列中需要包含的信息如下表:
| 属性 | 描述 |
|---|---|
| 列名 | 索引列名称,用户在检索中指定在某列中进行匹配查询 |
| 索引类型 | 目前只开放了向量图索引类型 |
| 数据类型 | 描述当前列中数据的类型,不同于传统的int8, int32,string等基础类型,向量类型一般会附加上vector前缀,比如说描述一个int8的向量,它对应的类型是vector_int8。 |
| 维度 | 描述数据所具有的维度空间(只有数据类型为向量时,此属性有效) |
| 高级属性 | 针对特定索引类型有效的高阶参数列表 |
3. 存储
3.1. 元数据存储
系统中元数据目前统一存储在Sqlite中,用户在生产环境中使用时请配置meta的存储路径为共享存储目录,详情参见高阶配置
3.2. 集合数据存储模式
BE属于列存储模式,相同列的数据紧凑存储,多列数据以行分片的模式相邻存储在同一文件内,集合文档的逻辑视图与存储视图如下表:
---
scale: 55
---
4. 元数据管理
BE中开放了元数据的管理API, 用户可通过BE API、SDK API进行元数据的管理工作,包含集合的增、删、改等功能
4.1. 使用BE API管理元数据
BE默认开放HTTP、GRPC两种协议API,HTTP API请参考文档RESTful HTTP, 对性能有需求的用户建议采用GRPC协议,接入方式可联系BE的开发团队接洽。
4.2. 使用SDK管理元数据
BE目前提供四种语言的SDK,请参考相关的SDK文档:
3.3 - 监控报警
ProximaBE 基于 brpc 的 bvar 功能,实现了兼容 Prometheus 的监控功能。
基本流程如下
- ProximaBE 配置使用 bvar 做监控。
- 配置 Prometheus,从 ProximaBE 订阅。
- 配置 Grafana,便于查询监控。
1. 配置 bvar
修改 proxima_be.conf,设置 common_config.metrics_config.name 为 bvar。
common_config {
# ...
metrics_config {
name: "bvar"
}
# ...
}
2. 配置 Prometheus
在 prometheus.yml 中的 scrape_configs 中,加入如下配置
- job_name: 'proxima-be'
# metrics_path defaults to '/metrics'
metrics_path: '/brpc_metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:16000']
完整的 prometheus.yml 可以从这里下载。
然后启动 prometheus(下载地址)
$ ./prometheus --config.file=prometheus.yml
3. 配置Grafana
- 启动并配置 Grafana
docker run -i -p 3000:3000 grafana/grafana - 在浏览器中打开 Grafana(地址如 http://localhost:3000/),并登录Grafana用户交互页面。
- 添加 Prometheus 数据源,参考官方文档
- 下载 Grafana配置文件,参考官方文档导入 Grafana。

3.4 - Repository
1. 基本概念
Repository 主要对数据源进行抽象。对于需要用于构建索引的数据可能存储在不同的存储系统中,比如 MySQL 数据库、Postgres 数据库和文件等等。为了支持从不同的存储系统中获取数据并把数据传送到 ProximaBE 用于后续的索引构建,我们提出了 Repository 的概念。 Repository 能够对接不同的存储系统,根据不同的存储系统实现相关的数据同步逻辑,并把数据的增、删、改等变化同步给 ProximaBE,从而使得相应的索引发生相应的变化。如下图所示:
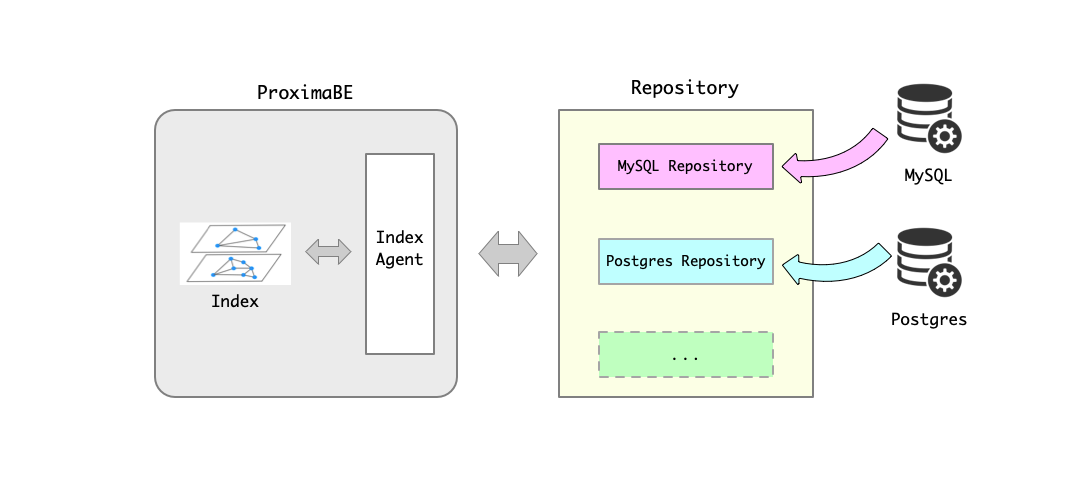
Repository 模块使得检索服务和原始数据的存储服务分离。从而拓展了 ProximaBE 的应用场景,增强了系统的可拓展性。当需要支持新的存储系统时,仅需实现相应的 Repository ,而不会影响 ProximaBE 的检索服务。
2. Repository 类型
按照设计每种存储系统对应一个相应的 Repository。例如,对于 MySQL 数据库对应的为 MySQL Repository,对于 Postgres 数据库对应 Postgres Repository 等等。 当前版本中仅支持 MySQL Repository,后续根据需要会添加 Postgres Repository 等更多的 Repository。
3. MySQL Repository
3.1. 基本概念
MySQL Repository 对接的数据源为 MySQL 数据库。MySQL Repository 利用 MySQL 的主从复制原理实现对 MySQL 数据库的实时订阅。
MySQL 的主从复制原理如下图所示:
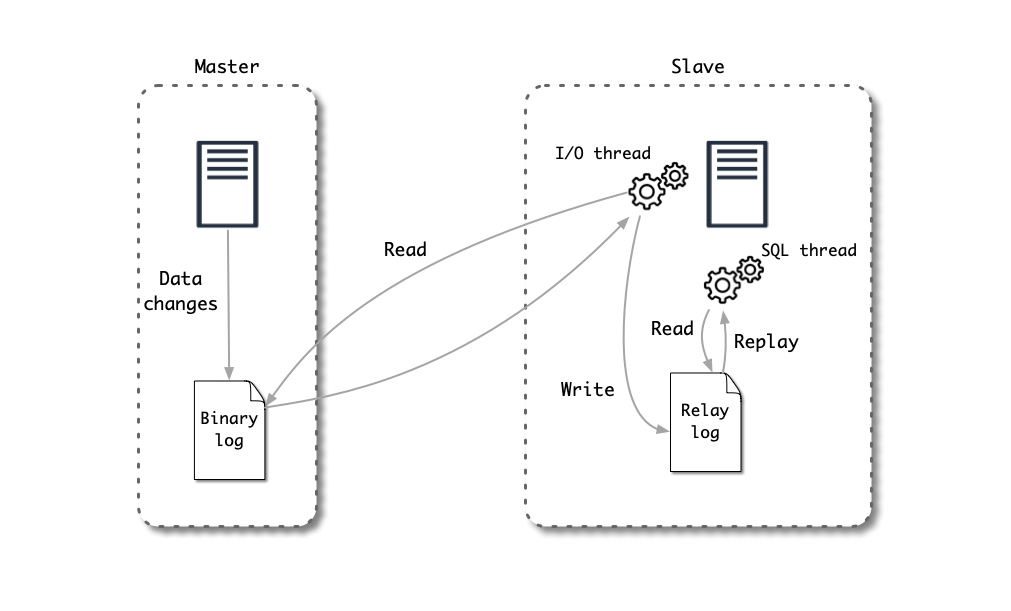
- MySQL 主服务器 (master) 将数据变更写入二进制日志( binary log)
- MySQL 从服务器 (slave) 将主服务器的 binary log 中的事件(event) 拷贝到它的中继日志(relay log)
- MySQL 从服务器重放中继日志中的事件,将数据变更反映它自己的数据中
MySQL Repository 的工作原理:
- MySQL Repository 模拟 MySQL Replica 原理,把自己伪装为 MySQL 从服务器,向 MySQL 主服务器发送 dump 请求
- MySQL 主服务器收到 dump 请求,开始推送 binlog 给 MySQL Repository
- MySQL Repository 解析相应的 binlog,解析为 ProximaBE 所需要的数据格式后发送给 ProximaBE
- ProximaBE 中的 Index Agent 模块接收到数据,并把数据传送给后续的索引构建模块
3.2. 快速开始
第一步: MySQL 基本设置
为了保证能够通过 binlog 正确获取 MySQL 数据库中数据,数据库和数据需要符合特定的设置:
- MySQL 版本 5.7.x
- 开启 binlog
- binlog 记录模式为 ROW 模式
- 表结构中含有自增列
MySQL 可以在文件 my.cnf 文件中进行设置。示例如下代码所示:
[mysqld]
server-id = 12000
log_bin = binlog
binlog_format = ROW
以 Docker 启动 MySQL:
$ docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
第二步: 拉取 MySQL Repository 镜像
安装前提见快速入门部分。这里不再赘述。
拉取 MySQL Repository Docker 镜像:
$ sudo docker pull ghcr.io/proximabilin/proxima-be
第三步: MySQL Repository 配置
创建配置文件、log 文件、数据文件所存储的路径:
$ mkdir -p $HOME/proxima-be/{conf,data,log}
首先需要启动 ProximaBE ,启动方式可以参照快速入门所述,这里不再赘述。在本示例中,假设 ProximaBE 和 MySQL Repository 在同一台机器且 ProximaBE 的 grpc_listen_port 为 16000。则 MySQL Repository 相应的配置文件可以如下所示: ( 位置:$HOME/proxima-be/conf/mysql_repo.conf):
common_config {
log_directory: "/var/lib/proxima-be/log/"
log_file: "mysql_repo.log"
}
repository_config {
index_agent_addr: "127.0.0.1:16000"
}
NOTE : 以上配置中 index_agent_addr 和 ProximaBE 的配置有关。表示 ProximaBE 的 IP 地址和 ProximaBE 的grpc_listen_port 值。
第四步: 映射文件启动容器
$ sudo docker run -d --name mysql-repository \
-v $HOME/proxima-be/conf:/var/lib/proxima-be/conf \
-v $HOME/proxima-be/data:/var/lib/proxima-be/data \
-v $HOME/proxima-be/log:/var/lib/proxima-be/log \
ghcr.io/proximabilin/proxima-be \
/var/lib/proxima-be/bin/mysql_repository --config /var/lib/proxima-be/conf/mysql_repo.conf
3.3. 详细配置
Common Config:
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| logger_type | string | “RepositoryAppendLogger” | 否 | 目前支持一种Logger RepositoryAppendLogger–自动增加切割日志 |
| log_directory | string | “./log/” | 否 | 日志目录 |
| log_file | string | “mysql_repository.log” | 否 | 日志名称 |
| log_level | uint32 | 2 | 否 | 最低打印日志级别 1–DEBUG 2–INFO 3–WARN 4–ERROR 5–FATAL |
Repository Config:
| 参数名 | 类型 | 默认值 | 必需 | 说明 |
|---|---|---|---|---|
| index_agent_addr | string | “0.0.0.0:16000” | 是 | index agent IP 地址和端口号 |
| repository_name | string | “mysql_repository” | 否 | repository 名字 |
| load_balance | string | "" | 否 | RPC 负载均衡 |
| batch_size | uint32 | 64 | 否 | Repository 向 ProximaBE 传送数据的最大 batch 大小 |
| batch_interval | uint32 | 5000 | 否 | Repository 向 ProximaBE 传送数据的最大时间间隔。单位“微妙” |
| max_retry | int | 3 | 否 | RPC 重试次数 |
| timeout_ms | int | 500 | 否 | RPC 超时时间,单位“毫秒” |
3.4. MySQL 表配置说明
想要要通过 MySQL Repository 的方式来自动进行数据同步,需要满足下面几点:
- 用户定义的 MySQL 表中必须含有一个自增列 ID。
- 在集合中定义的向量索引字段,在 MySQL 表中对应的字段必须是 VARCHAR 类型,格式为 Json Array 的字符串,其它格式的暂时不支持,例如:
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0] - 在集合中定义的向量正排字段,可以是 MySQL 中支持的常规类型,目前 geometry 和 json 等复杂类型暂时不支持配置。
示例:
# 1、创建MySQL表
CREATE TABLE `test_table` (
`id` int(11) NOT NULL AUTO_INCREMENT, # 自增列 ID
`name` varchar(64) NOT NULL, # 姓名
`age` int(11) NOT NULL, # 年龄
`score` float NOT NULL, # 信用分
`face` varchar(10240) NOT NULL, # 人脸向量,假定为4维的float
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 2、插入数据
insert into test_table(name, age, score, face) values ('xiaoming', 23, 95.3, '[1.0, 2.0, 3.0, 4.0]');
insert into test_table(name, age, score, face) values ('xiaohua', 24, 85.3, '[2.5, 3.0, 3.5, 4.5]');
# 3、创建集合的配置
# face -> 向量索引列(IndexColumn)
# id, name, age, score -> 正排列(ForwardColumn)
3.5 - 性能调优
3.6 - 常用工具
在 Proxima BE 发布的镜像中,附带了几个常用工具,主要是方便客户管理 collection 和文档。
1. 如何获取
相关工具位于镜像 ghcr.io/proximabilin/proxima-be 的目录 /var/lib/proxima-be/bin/
2. admin_client
2.1 使用方法
$ admin_client -h
Usage:
admin_client <args>
Args:
--command Command type: create | drop
--host The host of proxima be, http port
--collection Specify collection name
--schema Specify collection schema format
--help, -h Display help info
--version, -v Dipslay version info
2.2 创建Collection
$ admin_client --command create --host 127.0.0.1:16001 --collection test_collection \
--schema '{"collection_name":"test_collection", "index_column_params":[{"column_name":"test_column",
"index_type": "IT_PROXIMA_GRAPH_INDEX", "data_type":"DT_VECTOR_FP32", "dimension":8}]}'
2.3 删除Collection
$ admin_client --command drop --host 127.0.0.1:16001 --collection test_collection
3. bench_client
3.1 使用方法
$ bench_client -h
Usage:
bench_client <args>
Args:
--command Command type: search|insert|delete|update
--host The host of proxima be
--collection Specify collection name
--column Specify column name
--file Read input data from file
--protocol Protocol http or grpc
--concurrency Send concurrency (default 10)
--topk Topk results (default 10)
--perf Output perf result (default false)
--help, -h Display help info
--version, -v Display version info
3.2 插入数据
$ bench_client --command insert --host 127.0.0.1:16000 --collection test_collection --column test_column --file
data.txt
数据格式支持明文和二进制两种,key与向量之间用";“分隔,多维向量采用空间分割,样例数据如下:
0;-0.009256 -0.079674 -0.070349 0.007072 -0.064061 -0.010632 0.083429 -0.074821
1;-0.061519 -0.001263 -0.016528 0.031539 0.041385 -0.017736 -0.005704 0.129443
2;-0.039616 -0.063191 0.057591 -0.090278 -0.007452 -0.035939 -0.021892 -0.037860
3;0.042097 0.050037 0.055060 0.150511 -0.052841 -0.005502 -0.018618 0.054607
3.3 查询数据
query数据格式同上述的插入数据格式相同。
$ bench_client --command search --host 127.0.0.1:16000 --collection test_collection --column test_column --file
query.txt
3.4 删除数据
data数据格式同上述的插入数据格式相同。
$ bench_client --command delete --host 127.0.0.1:16000 --collection test_collection --column test_column --file
data.txt
4. index_builder
对于数据集已经提前准备好的场景,为加速索引构建,可通过离线构建工具加速构建。
4.1 使用方法
Usage:
index_builder <args>
Args:
--schema Specify the schema of collection
--file Specify input data file
--output Sepecify output index directory(default ./)
--concurrency Sepecify threads count for building index(default 10)
--help, -h Dipslay help info
--version, -v Dipslay version info
4.2 数据文件格式说明
每行一条记录,由 ‘;’ 分隔。分别是 key,向量,正排属性。其中 key 为 uint64 类型,向量各维度用 ' ' 分隔。属性可选。例如
111;1.0 1.1 1.2 1.3;a,b
4.3 使用示例
test.txt 内容为上述内容的文件。则构建索引可用如下命令:
index_builder --output index --schema '{"collection_name":"test_collection", "forward_column_names":["k1"], "index_column_params":[{"column_name":"test_column",
"index_type": "IT_PROXIMA_GRAPH_INDEX", "data_type":"DT_VECTOR_FP32", "dimension":4}]}' --file test.txt
4.3 使用注意
由于离线工具构建的索引没有相应 meta 信息。如果作为 Proxima SE 提供检索能力。需要创建一个对应的 collection。 例如启动 proxima_se 服务时,配置好相应的索引位置为 index:
common_config {
grpc_listen_port: 16000
http_listen_port: 16001
}
index_config {
index_directory: "index/"
}
query_config {
query_thread_count: 8
}
启动后,使用如下命令创建相应集合。
curl -X POST http://0.0.0.0:16001/v1/collection/test_collection -d '{"collection_name":"test_collection", "forward_column_names":["k1"], "index_column_params":[{"column_name":"test_column","index_type": "IT_PROXIMA_GRAPH_INDEX", "data_type":"DT_VECTOR_FP32", "dimension":4}]}'
然后进行检索
curl -X POST \
http://0.0.0.0:16001/v1/collection/test_collection/query \
-d '{
"knn_param":{
"column_name":"test_column",
"topk":10,
"matrix":"[[1.0, 2.0, 3.0, 4.0]]",
"batch_count":1,
"dimension":4,
"data_type":"DT_VECTOR_FP32",
"is_linear":true,
}
}'
# 返回
{"status":{"code":0,"reason":"Success"},"results":[{"documents":[{"score":11.34,"primary_key":"111","forward_column_values":[{"key":"k1","value":{"string_value":"a,b"}}]}]}],"debug_info":"","latency_us":"902"}
4 - API 手册
4.1 - REST APIs
ProximaBE 同时提供了 RESTful API,以及 GRPC API 两种协议,以满足在不同应用场景下的集成需求(相较于 GRPC协议,RESTful API 有明显的适用范围、语言原生支持的优势),对于性能敏感的应用场景,建议使用GRPC协议,将在后续进行讲解。
目前支持的 APIs 列表,可统分为两类api,一类是集合管理接口,另外一类是文档管理接口。
1 版本
请求:
$ HTTP 1.1 GET /service_version
返回值:
- status: ProximaBE 执行状态 服务器执行状态
- version:String, 发布版本的字符串标识
示例:
# Example: Get the version of ProximaBE
##################################################
# Request:
curl -X GET \
http://11.122.49.225:16100/service_version \
-H 'cache-control: no-cache'
##################################################
# Response:
{
"status": {
"code": 0,
"reason": "Success"
},
"version": "0.1.0-50-g16af91e"
}
2. 集合管理
用户可通过 API 进行集合的增、删、改(退后发布)、查等功能。
2.1 集合增、删、查
目前发布的 ProximaBE 0.1.0 版本中暂不支持集合的更新操作。
2.1.1 创建集合
请求:
$ HTTP 1.1 POST /v1/collection/{name}
路径参数:
- name: 需要创建的集合名称(需全局唯一)
请求主体:
- collection_name:String 可选参数, 默认与路径参数同名
- max_docs_per_segment: Uint64 可选参数,默认值为系统最大值~(uint64)0, 设置集合数据的分片大小阈值。
- forward_column_names:List[String,…] 可选参数, 正排名列表,定义用户为文档关联的属性列表。
- index_column_params:List[IndexColumnParam,…], 索引列表
- column_name: String, 索引列名称
- index_type: String, 索引类型名,可选参数如下表:
- IT_PROXIMA_GRAPH_INDEX: 图式索引
- data_type: DataTypes, 索引列数据类型,只能使用字符串标识
- dimension: Uint32, 数据维数,仅针对向量列有效
- extra_params: List[KeyValuePair,…], 高阶参数列表
- key: *String, * 参数名称
- value: “String, " 参数值
返回值:
请参考:ProximaBE 执行状态
示例:
# Example: Create Collection with two index colums
##################################################
# Request:
curl -X POST \
http://11.122.49.225:16100/v1/collection/example \
-H 'cache-control: no-cache' \
-H 'content-type: application/json' \
-d '{
"collection_name":"example",
"forward_column_names":[
"forward",
"forward1"
],
"index_column_params":[
{
"column_name":"column",
"index_type":"IT_PROXIMA_GRAPH_INDEX",
"data_type":"DT_VECTOR_FP32",
"dimension":8,
"extra_params":[
{
"key":"ef_search",
"value":"200"
}
]
},
{
"column_name":"column1",
"index_type":"IT_PROXIMA_GRAPH_INDEX",
"data_type":"DT_VECTOR_FP16",
"dimension":128
}
]
}'
##################################################
# Response:
{
"code": 0,
"reason": ""
}
2.1.2 查询集合
请求:
$ HTTP 1.1 GET /v1/collection/{name}
路径参数:
- name: 需要查询的集合名称
返回值: (CollectionInfo)=
- status: Status, 服务执行状态状态
- collection: CollectionInfo, 集合详细信息
- uuid: String, 集合全局唯一ID
- status: String, 集合状态码,可选值如下:
- CS_INITIALIZED: 集合已初始化完成
- CS_SERVING: 集合正常提供服务
- CS_DROPPED: 集合已删除
- magic_number: Uint64, 集合魔法数
- config: *CollectionConfig, * 请参考创建集合的请求主体
示例:
# Example: Describe Collection
##################################################
# Request:
curl -X GET \
http://11.122.49.225:16100/v1/collection/example \
-H 'cache-control: no-cache'
##################################################
# Response:
{
"status": {
"code": 0,
"reason": ""
},
"collection": {
"uuid": "d918becac22e471db41d55050809b8af",
"config": {
"collection_name": "example",
"index_column_params": [
{
"data_type": "DT_VECTOR_FP16",
"dimension": 128,
"index_type": "IT_PROXIMA_GRAPH_INDEX",
"column_name": "column1",
"extra_params": []
},
{
"data_type": "DT_VECTOR_FP32",
"dimension": 8,
"index_type": "IT_PROXIMA_GRAPH_INDEX",
"column_name": "column",
"extra_params": [
{
"key": "ef_search",
"value": "200"
}
]
}
],
"forward_column_names": [
"forward",
"forward1"
],
"max_docs_per_segment": "18446744073709551615"
},
"status": "CS_SERVING",
"magic_number": "0"
}
}
2.1.3 删除集合
请求:
$ HTTP 1.1 DELETE /v1/collection/{name}
路径参数:
- name: 需要删除的集合名称
返回值:
请参考:ProximaBE 执行状态
示例:
# Example: Delete Collection
##################################################
# Request:
curl -X DELETE \
http://11.122.49.225:16100/v1/collection/example \
-H 'cache-control: no-cache'
##################################################
# Response:
{
"code": 0,
"reason": ""
}
2.2 集合统计
获取集合的统计信息,其中包含不仅限于文件数,大小,文档个数等信息。
请求:
$ HTTP 1.1 GET /v1/collection/{name}/stats
路径参数:
- name: 需要获取统计信息的集合名称
返回值:
- status: ProximaBE 执行状态
- collection_stats: CollectionStats, 集合统计信息,完整定义如下:
- collection_name: String, 集合名称
- collection_path: String, 集合的存储路径
- total_doc_count: String, 集合的总文档个数
- total_segment_count: String, 集合分片个数
- total_index_file_size: String, 集合总的存储大小
- total_index_file_count: String, 集合内总的文件个数
- segment_stats: SegmentStats, 分片统计信息列表,多片模式下会有多个结果
- state: String, 分片状态码,可能的值罗列如下:
- SS_WRITING: 分片正在写入
- max_lsn: String, 分片内最大的记录号
- min_lsn: String, 分片内最小的记录号
- doc_count: String, 分片内文档个数
- max_doc_id: String, 分片内最大文档ID
- min_doc_id: String, 分片内最小文档ID
- segment_id: Uint32, 分片编号
- segment_path: String, 分片的存储路径
- max_timestamp: String, 分片内文档的最大时间戳
- min_timestamp: String, 分片内文档的最小时间戳
- index_file_size: String, 分片的存储大小
- max_primary_key: String, 分片内文档最大的主键值
- min_primary_key: String, 分片内文档最小的主键值
- index_file_count: Uint32, 分片内文件个数
- state: String, 分片状态码,可能的值罗列如下:
示例:
# Example: Stats Collection
##################################################
# Request:
curl -X GET \
http://11.122.49.225:16100/v1/collection/example/stats \
-H 'cache-control: no-cache'
##################################################
# Response:
{
"status": {
"code": 0,
"reason": ""
},
"collection_stats": {
"segment_stats": [
{
"state": "SS_WRITING",
"max_lsn": "0",
"min_lsn": "4294967295",
"doc_count": "0",
"max_doc_id": "0",
"min_doc_id": "0",
"segment_id": 0,
"segment_path": "",
"max_timestamp": "0",
"min_timestamp": "4294967295",
"index_file_size": "3223552",
"max_primary_key": "0",
"min_primary_key": "4294967295",
"index_file_count": "3"
}
],
"collection_name": "example",
"collection_path": "/home/xiaoxin.gxx/workspace/test/r/indices/example",
"total_doc_count": "0",
"total_segment_count": "1",
"total_index_file_size": "7913472",
"total_index_file_count": "7"
}
}
2.3 获取集合列表
获取满足条件的集合列表,当请求参数没有时默认为获取所有集合。
请求:
$ HTTP 1.1 GET /v1/collections?repo={repo}
请求参数:
- repo: 可选, 获取已关联到指定Repo的集合列表
返回值:
- status: ProximaBE 执行状态
- collections: {ref}
CollectionInfo <CollectionInfo>, 满足条件的集合列表
示例:
# Example: List Collections
##################################################
# Request:
curl -X GET \
http://11.122.49.225:16100/v1/collections?repo= \
-H 'cache-control: no-cache'
##################################################
# Response:
{
"status": {
"code": 0,
"reason": ""
},
"collections": [
{
"uuid": "d918becac22e471db41d55050809b8af",
"config": {
"collection_name": "example",
"index_column_params": [
{
"data_type": "DT_VECTOR_FP16",
"dimension": 128,
"index_type": "IT_PROXIMA_GRAPH_INDEX",
"column_name": "column1",
"extra_params": []
},
{
"data_type": "DT_VECTOR_FP32",
"dimension": 8,
"index_type": "IT_PROXIMA_GRAPH_INDEX",
"column_name": "column",
"extra_params": [
{
"key": "ef_search",
"value": "200"
}
]
}
],
"forward_column_names": [
"forward",
"forward1"
],
"max_docs_per_segment": "18446744073709551615"
},
"status": "CS_SERVING",
"magic_number": "0"
},
{
"uuid": "620976bd0d6728bb5ad566912f457066",
"config": {
"collection_name": "example3",
"index_column_params": [
{
"data_type": "DT_VECTOR_FP16",
"dimension": 128,
"index_type": "IT_PROXIMA_GRAPH_INDEX",
"column_name": "column1",
"extra_params": []
},
{
"data_type": "DT_VECTOR_FP32",
"dimension": 8,
"index_type": "IT_PROXIMA_GRAPH_INDEX",
"column_name": "column",
"extra_params": [
{
"key": "ef_search",
"value": "200"
}
]
}
],
"forward_column_names": [
"forward",
"forward1"
],
"max_docs_per_segment": "18446744073709551615"
},
"status": "CS_SERVING",
"magic_number": "0"
}
]
}
3 文档管理
3.1 文档插入、删除、更新
通过指定Rows[*].Row.operation_type可进行不同的文档操作
请求:
$ HTTP 1.1 POST /v1/collection/{name}/index
请求主体:
- request_id: String, 可选参数 请求ID(用于与外部系统关联)
- collection_name:String 可选参数, 默认与路径参数同名
- row_meta: RowMeta, 集合描述信息,其中包含正排列名称列表,以及索引列列表
- forward_column_names: List[String], 正排列名称列表
- index_olumn#95;metas: List[IndexColumnMeta], 索引列配置列表
- column_name: String, 索引列名称
- data_type: DataTypes, 索引列数据类型
- dimension: Uint32, 索引列数据维度(仅针对向量列有效)
- rows: List[4.3 文档数据…], 文档数据列表
- magic_number: String, 可选参数 字符串标识的64位无符号整数,魔数(用于与外部系统关联)
返回值:
请参考:ProximaBE 执行状态
示例:
# Example: Insert document into collection
##################################################
# Request:
curl -X POST \
http://11.122.49.225:16100/v1/collection/example/index \
-H 'cache-control: no-cache' \
-H 'content-type: application/json' \
-d '{
"collection_name":"example",
"row_meta":{
"forward_column_names":[
"forward",
"forward1"
],
"index_column_metas":[
{
"column_name":"column",
"data_type":"DT_VECTOR_FP32",
"dimension":8
}
]
},
"rows":[
{
"primary_key":"5",
"index_column_values":{
"values":[
{
"string_value":"[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]"
}
]
},
"forward_column_values":{
"values":[
{
"int64_value":"1"
},
{
"float_value":1.1
}
]
}
},
{
"primary_key":"3",
"index_column_values":{
"values":[
{
"bytes_value":"QagAAEGwAABBuAAAQcAAAEHIAABB0AAAQdgAAEHgAAA="
}
]
},
"forward_column_values":{
"values":[
{
"int64_value":"2"
},
{
"float_value":2.2
}
]
},
"lsn_context":{
"context":"write context hear"
}
}
]
}'
##################################################
# Response:
{
"code": 0,
"reason": "Success"
}
3.2 文档查询
执行近邻搜索
请求:
HTTP 1.1 POST /v1/collection/{name}/query
请求主体:
- collection_name:String 可选参数, 默认与路径参数同名
- debug_mode: Bool, 可选参数, 打开调试模式,该操作会加大请求的latency,请不要在生产环境中使用。
- knn_param: 4.4 KnnQueryParam, 近邻搜索请求参数
返回值:
- status: ProximaBE 执行状态, 查询请求状态
- results: List[4.5 文档列表,…] 文档列表
- debug_info: String, Json格式的字符串表达
- latency_us: String, 请求延时
示例:
# Example: Execute KNN Query
##################################################
# Request:
curl -X POST \
http://11.122.49.225:16100/v1/collection/example/query \
-H 'cache-control: no-cache' \
-H 'content-type: application/json' \
-d '{
"collection_name":"example",
"debug_mode":true,
"knn_param":{
"column_name":"column",
"topk":10,
"matrix":"[[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0], [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0], [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0], [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]]",
"batch_count":4,
"dimension":8,
"data_type":"DT_VECTOR_FP32",
"radius":1.5,
"is_linear":true,
"extra_params":[
{
"key":"customize_param",
"value":"10"
},
{
"key":"customize_param2",
"value":"1"
},
{
"key":"customize_param3",
"value":"str"
}
]
}
}'
##################################################
# Response:
{
"status": {
"code": 0,
"reason": "Success"
},
"results": [
{
"documents": []
},
{
"documents": [
{
"score": 0,
"primary_key": "0",
"forward_column_values": [
{
"key": "forward",
"value": {
"int64_value": "1"
}
},
{
"key": "forward1",
"value": {
"float_value": 1.1
}
},
{
"key": "forward2",
"value": {
"bool_value": true
}
}
]
},
{
"score": 0,
"primary_key": "2",
"forward_column_values": [
{
"key": "forward",
"value": {
"int64_value": "2"
}
},
{
"key": "forward1",
"value": {
"float_value": 2.2
}
},
{
"key": "forward2",
"value": {
"bool_value": false
}
}
]
}
]
},
{
"documents": [
{
"score": 0,
"primary_key": "0",
"forward_column_values": [
{
"key": "forward",
"value": {
"int64_value": "1"
}
},
{
"key": "forward1",
"value": {
"float_value": 1.1
}
},
{
"key": "forward2",
"value": {
"bool_value": true
}
}
]
},
{
"score": 0,
"primary_key": "2",
"forward_column_values": [
{
"key": "forward",
"value": {
"int64_value": "2"
}
},
{
"key": "forward1",
"value": {
"float_value": 2.2
}
},
{
"key": "forward2",
"value": {
"bool_value": false
}
}
]
}
]
},
{
"documents": [
{
"score": 0,
"primary_key": "0",
"forward_column_values": [
{
"key": "forward",
"value": {
"int64_value": "1"
}
},
{
"key": "forward1",
"value": {
"float_value": 1.1
}
},
{
"key": "forward2",
"value": {
"bool_value": true
}
}
]
},
{
"score": 0,
"primary_key": "2",
"forward_column_values": [
{
"key": "forward",
"value": {
"int64_value": "2"
}
},
{
"key": "forward1",
"value": {
"float_value": 2.2
}
},
{
"key": "forward2",
"value": {
"bool_value": false
}
}
]
}
]
}
],
"debug_info": "{\"query\":{\"latency\":205,\"prepare\":51,\"evaluate\":{\"execute\":102,\"latency\":139,\"merge_and_sort\":34},\"validate\":10},\"latency\":277,\"query_id\":11}",
"latency_us": "585"
}
3.3 根据主键查询文档
请求:
HTTP 1.1 GET /v1/collection/{name}/doc?key={key}
请求参数:
- key: Uint64, 指定文档主键
返回值:
- status: ProximaBE 执行状态, 查询请求状态
- results: List[4.6 文档,…] 文档
- debug_info: String, Json格式的字符串表达
示例:
# Example: Query document by key
##################################################
# Request:
curl -X GET \
'http://11.122.49.225:16100/v1/collection/example/doc?key=2' \
-H 'cache-control: no-cache'
##################################################
# Response:
{
"status": {
"code": 0,
"reason": "Success"
},
"document": {
"score": 0,
"primary_key": "2",
"forward_column_values": [
{
"key": "forward",
"value": {
"int64_value": "2"
}
},
{
"key": "forward1",
"value": {
"float_value": 2.2
}
},
{
"key": "forward2",
"value": {
"bool_value": false
}
}
]
},
"debug_info": ""
}
4 通用数据类型
4.1 执行状态
Status:
- code:Int32, 服务器指定状态码,0表示正常执行,非零代表执行错误,并设置reason字段为具体错误信息
- reason: String 可选参数, 附加错误信息
4.2 索引列数据类型
DataTypes: String, 标识索引列类型,可选类型如下:
- DT_VECTOR_BINARY32: 多维向量类型,每一维数据为32位二进制数据
- DT_VECTOR_BINARY64: 多维向量类型,每一维数据为64位二进制数据
- DT_VECTOR_FP16: 多维向量类型,每一维数据为16位浮点数
- DT_VECTOR_FP32: 多维向量类型,每一维数据为32位浮点数
- DT_VECTOR_INT8: 多维向量类型,每一维数据为8位有符号整数
4.3 文档数据
Row:
- primary_key: Uint64,非必须字段 文档主键
- operation_type: String, 字符串标识的操作类型,可选列表如下:
- OP_INSERT: 将该文档做插入操作
- OP_UPDATE: primary_key为主键更新该文档
- OP_DELETE: 删除primary_key为主键的文档
- index_column_values: 向量列数据
- values:
- bytes_value: String, base64位编码后的向量数据
- string_value: String, json字符串格式的向量数据,与bytes_value二选一即可
- values:
- forward_column_values: 正排列数据
- values: 正排数据列表,通过不同的主键标识数据类型
- bytes_value: String, base64位编码后的二进制数据
- string_value: String, 字符串数据
- bool_value: Bool, 布尔型数据,可选[true, false]
- int32_value: Int32, 32位有符号整数
- int64_value: String, 字符串标识的64位有符号整数
- uint32_value: Uint32, 32位无符号整数
- uint64_value: Uint64, 字符串标识的64位无符号整数
- float_value: Float, 32位浮点数
- double_value: Double, 32位浮点数
- values: 正排数据列表,通过不同的主键标识数据类型
- lsn_context: 4_4 LsnContext,非必须字段, 文档上下文(用于标识唯一的来源,一般用于数据同步场景)
示例1: base64编码的向量数据
{
"index_column_values":{
"values":[
{
"bytes_value":"P4AAAEAAAABAQAAAQIAAAECgAABAwAAAQOAAAEEAAAA="
}
]
},
"forward_column_values":{
"values":[
{
"int64_value":"1"
},
{
"float_value":1.1
}
]
}
}
示例2: json字符串格式向量数据
{
"index_column_values":{
"values":[
{
"string_value":"[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]"
}
]
},
"forward_column_values":{
"values":[
{
"int64_value":"1"
},
{
"float_value":1.1
}
]
}
}
4.4 记录上下文
LsnContext:
4.5 近邻检索参数
KnnQueryParam:
- column_name: String, 索引列名称
- topk: Uint32, topn最近的邻居个数
- 请求向量列表(以下参数二选一即可):
- matrix: List[List[String]…], Json格式的向量请求列表,可以发多个
- features: String, 字符串标识的请求向量(需Base64编码),如果是批量请求,需连续编码无间隔字符
- batch_count: Uint32, 批量请求的个数
- dimension: Uint32, 向量维度
- data_type: 4.2 DataType, 请参考DataType定义
- radius: Float, 搜索半径,不同距离函数下搜索半径取值不同
- is_linear: Bool, 线性搜索标志
- extra_params: Map[String, String], 附加搜索参数(暂不开放)
4.6 文档列表
Documents:
- documents: List[4.6 文档,…]
4.7 文档
Document:
- score: Float, 评分
- primary_key: Uint64, 字符串格式的64位整数
- forward_column_values: List[正排字段, …]
4.8 正排字段
Property:
- key: String, 属性名称
- value: 4.3 文档数据Value, 可变属性值
5 - SDK 手册
5.1 - Python SDK
目前只支持python 3.6及以上的版本。
1. 创建客户端
可以创建同步客户端或者异步客户端。
- 同步客户端
from pyproximabe import *
client = Client('127.0.0.1', 16000)
Proxima BE服务支持 GRPC 和 HTTP 两种协议,监听在不同的端口上。同步客户端同时支持这两种协议,默认使用GRPC协议。如果有需求,可以用下面的方式来指定协议。
client = Client('127.0.0.1', 16001, 'http')
- 异步客户端
from pyproximabe import *
client = AsyncClient(HOST, GRPC_PORT)
异步客户端基于asyncio实现,除了需要await结果外,和同步客户端的使用方式完全一致。 异步客户端只支持GRPC协议。
同步或异步客户端支持的参数如下
def __init__(self, host, port=16000, handler='grpc', timeout=10):
| 参数 | 说明 |
|---|---|
| host | 服务器地址,str类型 |
| port | 服务器端口,int类型 |
| handler | 协议类型,str类型,一般不需要指定。 同步客户端支持grpc/http,异步客户端只支持grpc。 |
| timeout | 超时时间,单位秒,float类型,默认为10。指定为None则不超时。 |
使用完毕后,可以调用close()关闭客户端,其参数为空,返回值为None。
client.close()
2. 集合管理
2.1. 集合创建
创建直写集合
collection_name = 'iris'
index_column = IndexColumnParam('length', 4, IndexType.PROXIMA_GRAPH_INDEX)
collection_config = CollectionConfig(collection_name, [index_column], ['iris_type'])
status = client.create_collection(collection_config)
if not status.ok():
# error handling
logging.error('create collection failed, status=%s', status)
首先,创建一个或多个索引列
index_column = IndexColumnParam('length', 4, IndexType.PROXIMA_GRAPH_INDEX)
参数如下
def __init__(self,
name,
dimension,
index_type=IndexType.PROXIMA_GRAPH_INDEX,
data_type=DataType.VECTOR_FP32,
extra_params=None):
| 参数 | 说明 |
|---|---|
| name | 索引列名称,str类型。 |
| dimension | 向量维度,int类型。 |
| index_type | 索引类型,IndexType 类型,默认为PROXIMA_GRAPH_INDEX。 |
| data_type | 数据类型,DataType 类型,默认为VECTOR_FP32。 |
| extra_params | 扩展参数,dict类型,默认为空。 |
然后,创建CollectionConfig。
collection_config = CollectionConfig(collection_name, [index_column], ['iris_type'])
(python_collection_config)= 参数如下
def __init__(self,
collection_name,
index_column_params,
forward_column_names=None,
repository_config=None,
max_docs_per_segment=0):
| 参数 | 说明 |
|---|---|
| collection_name | 集合名称,str类型。 |
| index_column_params | 索引列列表,List[IndexColumnParam]类型。 |
| forward_column_names | 正排列列表,List[str]类型。默认为空。 |
| repository_config | 仓库配置,DatabaseRepository类型。默认为None。 |
| max_docs_per_segment | 每个segment的最大文档数,long类型。默认为0,文档数不限。 |
最后,调用client接口。
status = client.create_collection(collection_config)
if not status.ok():
# error handling
logging.error('create collection failed, status=%s', status)
create_collection()接收CollectionConfig参数,返回ProximaBeStatus。
def create_collection(self, collection_config):
创建数据库旁路集合
MYSQL_PORT = 3306
MYSQL_HOST = HOST
mysql_table_name = 'iris_table'
mysql_database_name = 'test_db'
mysql_user='root'
mysql_password='root'
index_column = IndexColumnParam('length', 4, IndexType.PROXIMA_GRAPH_INDEX)
database_repository = DatabaseRepository('test_repository',
f'mysql://{MYSQL_HOST}:{MYSQL_PORT}/{mysql_database_name}',
mysql_table_name, mysql_user, mysql_password)
collection_config = CollectionConfig(collection_name, [index_column], ['iris_type'], database_repository)
status = client.create_collection(collection_config)
除了需要创建DatabaseRepository外,其他参数和直写集合完全相同。目前只支持mysql。
database_repository = DatabaseRepository('test_repository',
f'mysql://{MYSQL_HOST}:{MYSQL_PORT}/{mysql_database_name}',
mysql_table_name, mysql_user, mysql_password)
参数列表如下
def __init__(self, repository_name, connection_uri, table_name, user, password):
| 参数 | 说明 |
|---|---|
| repository_name | 仓库名称,str类型。 |
| connection_uri | 数据库连接串,str类型,如"mysql://localhost/database",不包含用户名和密码。 |
| table_name | 表名,str类型。 |
| user | 用户名,str类型。 |
| password | 数据库密码,str类型。 |
2.2. 描述集合
status, collection_info = client.describe_collection(collection_name)
if not status.ok():
pass # error handling
print(collection_info)
describe_collection()接收str类型的collection_name
def describe_collection(self, collection_name):
返回值有两个
2.3. 获取集合统计信息
status, collection_stats = client.stats_collection(collection_name)
if not status.ok():
pass # error handling
print(collection_stats)
stats_collection()接收str类型的collection_name
def stats_collection(self, collection_name):
返回值有两个
2.4. 删除集合
status = client.drop_collection(collection_name)
drop_collection()接收str类型的collection_name,返回ProximaBeStatus。
def drop_collection(self, collection_name):
2.5. 获取集合列表
status, collections_data = client.list_collections()
list_collections()参数列表如下
def list_collections(self, repository_name=None):
| 参数 | 说明 |
|---|---|
| repository_name | 仓库名称,str类型,默认为空。参数为空时,返回所有的集合列表,否则返回指定仓库下的集合列表。 |
| 返回值有两个 |
3. 文档管理
3.1. 通用接口
import struct
row_meta = WriteRequest.RowMeta([WriteRequest.IndexColumnMeta('length', 'VECTOR_FP32', 4)],
['iris_type'],
[DataType.STRING])
rows = [
WriteRequest.Row(100001,
WriteRequest.OperationType.INSERT,
[[5.9,3.0,5.1,1.8]],
['Iris-virginica']),
WriteRequest.Row(100002,
WriteRequest.OperationType.INSERT,
['[5.9,3.0,5.1,1.8]'],
['Iris-virginica']),
WriteRequest.Row(10002,
WriteRequest.OperationType.UPDATE,
[struct.pack('<4f', 5.9, 3.0, 5.1, 1.8)],
['Iris-virginica']),
WriteRequest.Row(10003, WriteRequest.OperationType.DELETE),
]
write_request = WriteRequest(collection_name, rows, row_meta)
status = client.write(write_request)
首先,创建WriteRequest.RowMeta,描述插入行的数据类型等信息。
row_meta = WriteRequest.RowMeta([WriteRequest.IndexColumnMeta('length', 'VECTOR_FP32', 4)],
['iris_type'],
[DataType.STRING])
WriteRequest.IndexColumnMeta的参数如下
def __init__(self, name, data_type, dimension):
| 参数 | 说明 |
|---|---|
| name | 索引列名称,str类型。 |
| data_type | 数据类型,DataType 类型。 |
| dimension | 向量维度,int类型。 |
WriteRequest.RowMeta的参数如下 |
def __init__(self,
index_column_metas,
forward_column_names=None,
forward_column_types=None):
| 参数 | 说明 |
|---|---|
| index_column_metas | 索引列列表,List[WriteRequest.IndexColumnMeta]类型。 |
| forward_column_names | 正排列名称列表,List[str]。默认为空。 |
| forward_column_types | 正排列类型列表,List[DataType]。默认为空。 |
然后创建WriteRequest.Row。
WriteRequest.Row(100001,
WriteRequest.OperationType.INSERT,
[[5.9,3.0,5.1,1.8]],
['Iris-virginica']),
WriteRequest.Row的参数如下
def __init__(self,
primary_key,
operation_type,
index_column_values=None,
forward_column_values=None,
lsn_context=None):
| 参数 | 说明 |
|---|---|
| primary_key | 主键,long类型。 |
| operation_type | 操作类型, WriteRequest.OperationType 类型。 |
| index_column_values | 索引列的值列表,list类型,operation_type为删除时不需要指定。支持三种类型
|
| forward_column_values | 正排列的值列表,list类型。 |
| lsn_context | 日志序列号上下文,LsnContext类型,默认为空。一般不需要设置。 |
然后创建WriteRequest |
write_request = WriteRequest(collection_name, rows, row_meta)
WriteRequest参数如下
def __init__(self,
collection_name,
rows,
row_meta=None,
request_id=None,
magic_number=None):
| 参数 | 说明 |
|---|---|
| collection_name | 集合名称,str类型。 |
| rows | 文档列表,List[WriteRequest.Row]类型。 |
| row_meta | 文档元数据,WriteRequest.RowMeta类型。如果所有的operation_type都为DELETE,不需要指定。 |
| request_id | 请求id,str类型,默认为空。一般不需要设置。 |
| magic_number | 服务端魔数,long类型,默认为0。一般不需要设置。 |
最后调用client接口。
status = client.write(write_request)
write()接收WriteRequest参数,返回ProximaBeStatus。
def write(self, write_request):
3.2. 删除接口
status = client.delete_document_by_keys(collection_name, [10001, 10002])
在只需要删除时,python sdk提供了简化接口,只需要指定集合名称和主键列表。 参数如下
def delete_document_by_keys(self, collection_name, primary_keys):
| 参数 | 说明 |
|---|---|
| collection_name | 集合名称,str类型。 |
| primary_keys | 主键列表,List[long]类型。 |
delete_document_by_keys()返回值为ProximaBeStatus。 |
4. 文档查询
4.1. 向量查询
status, knn_res = client.query(collection_name,
'length',
[[5.1, 3.5, 1.4, 0.2],
[5.5, 2.3, 4.0, 1.3]],
'VECTOR_FP32',
topk=2)
for i, result in enumerate(knn_res.results):
print(f'Query: {i}')
for doc in result:
forward_values = ','.join(
f'{k}={v}' for k, v in doc.forward_column_values.items())
print(
f' primary_key={doc.primary_key}, score={doc.score}, forward_column_values=[{forward_values}]'
)
query()的参数如下
def query(self,
collection_name,
column_name,
features,
data_type=None,
dimension=None,
batch_count=None,
topk=100,
is_linear=False,
radius=None,
extra_params=None):
| 参数 | 说明 |
|---|---|
| collection_name | 集合名称,str类型。 |
| column_name | 索引列名称,str类型。 |
| features | 特征,支持三种类型
|
| data_type | 数据类型,DataType 类型。默认为空。
|
| dimension | 向量维度,int类型。默认为空。
|
| batch_count | batch大小,int类型。默认为空。
|
| topk | 单条查询向量返回的结果数,int类型。默认为100。 |
| is_linear | 是否做线性查找,bool类型。默认为False,基于索引做查找。 |
| radius | 搜索半径,只返回以搜索向量为球心的球体内的向量,float类型。默认为0.0,搜索半径不限。 |
| extra_params | 扩展参数,dict类型。 |
| 返回值有两个 |
4.2. 主键查询
status, res = client.get_document_by_key(collection_name, primary_key=100001)
get_document_by_key()的参数如下
def get_document_by_key(self, collection_name, primary_key):
| 参数 | 说明 |
|---|---|
| collection_name | 集合名称,str类型。 |
| primary_key | 主键,long类型。 |
| 返回值有两个 |
- ProximaBeStatus。主键不存在时,status.ok() == True.
- Document。主键不存在时,返回None。
5. 错误处理
错误处理
python sdk接口一般会返回ProximaBeStatus类型,其包含两个属性
| 属性 | 说明 |
|---|---|
| code | 错误码,int类型。 |
| reason | 错误详情,str类型。 |
可以通过ok()接口来判断是否成功。
def ok(self):
return self.code == 0
:class: warning
请求服务端成功时才会返回ProximaBeStatus,如果客户端参数检查失败或者网络有问题,会抛出ProximaSeException异常。
class ProximaSeException(Exception):
pass
6. 类型定义
IndexType
class IndexType(IntEnum):
UNDEFINED = 0
PROXIMA_GRAPH_INDEX = 1
DataType
class DataType(IntEnum):
UNDEFINED = 0
BINARY = 1
STRING = 2
BOOL = 3
INT32 = 4
INT64 = 5
UINT32 = 6
UINT64 = 7
FLOAT = 8
DOUBLE = 9
VECTOR_BINARY32 = 20
VECTOR_BINARY64 = 21
VECTOR_FP16 = 22
VECTOR_FP32 = 23
VECTOR_FP64 = 24
VECTOR_INT4 = 25
VECTOR_INT8 = 26
VECTOR_INT16 = 27
WriteRequest.OperationType
class OperationType(IntEnum):
INSERT = 0
UPDATE = 1
DELETE = 2
Document
Document 包含以下属性
| 属性 | 说明 |
|---|---|
| primary_key | 主键,long类型。 |
| score | 分值,即距离查询向量的距离,float类型。 |
| forward_column_values | 正排名称到值的映射,dict类型。 |
QueryResponse
QueryResponse包含以下属性
| 属性 | 说明 |
|---|---|
| results | 结果列表,List[List[Document]]类型。第一重list表示多个查询向量的结果,第二重list表示每个向量的Document列表 |
| debug_info | 服务端调试信息,str类型。 |
| latency_us | 服务端统计的耗时,单位为微秒。 |
CollectionInfo
CollectionInfo包含以下属性
| 属性 | 说明 |
|---|---|
| collection_config | 集合配置, CollectionConfig类型。 |
| status | 集合状态,CollectionInfo.Status 类型。 |
| uuid | 集合唯一标识,str类型。 |
| latest_lsn_context | 最新日志序列号上下文, LsnContext 类型。 |
| magic_number | 服务端魔数,long类型。 |
{ref}CollectionConfig定义见这里<python_collection_config>
CollectionInfo.Status定义
class Status(IntEnum):
"""Collection Status"""
INITIALIZED = 0
SERVING = 1
DROPPED = 2
CollectionStats
CollectionStats包含以下属性
| 属性 | 说明 |
|---|---|
| collection_name | 集合名称,str类型。 |
| collection_path | 集合路径,str类型。 |
| total_doc_count | 文档总数,long类型。 |
| total_segment_count | 分段总个数,long类型。 |
| total_index_file_count | 索引文件总个数,long类型。 |
| total_index_file_size | 索引文件总大小,long类型。 |
| segment_stats | 分段统计信息,List[CollectionStats.SegmentStats]类型。 |
CollectionStats.SegmentStats包含以下属性
| 属性 | 说明 |
|---|---|
| segment_id | 段id,int类型。 |
| state | 段状态,CollectionStats.SegmentState类型。 |
| doc_count | 文档数,long类型。 |
| index_file_count | 索引文件个数,long类型。 |
| index_file_size | 索引文件大小,long类型。 |
| min_doc_id | 当前分段的最小文档id,long类型。 |
| max_doc_id | 当前分段的最大文档id,long类型。 |
| min_primary_key | 当前分段的最小主键,long类型。 |
| max_primary_key | 当前分段的最大主键,long类型。 |
| min_timestamp | 当前分段的最小时间戳,long类型。 |
| max_timestamp | 当前分段的最大时间戳,long类型。 |
| min_lsn | 当前分段的最小日志序列号,long类型。 |
| max_lsn | 当前分段的最大日志序列号,long类型。 |
| segment_path | 段文件路径,str类型。 |
CollectionStats.SegmentState定义如下
class SegmentState(IntEnum):
CREATED = 0
WRITING = 1
DUMPING = 2
COMPACTING = 3
PERSIST = 4
LsnContext
LsnContext 包含以下属性
| 属性 | 说明 |
|---|---|
| lsn | 序列号,long类型。 |
| context | 上下文,str类型。 |
7. 其他示例
8. Python API Reference
5.2 - C++ SDK
ProximaBE的C++ SDK主要是针对用户上游C/C++模块的集成,其具备高吞吐和低负载的特点,功能上主要是包含集合管理、文档读写等能力,可以节省用户的编码成本。
这篇文章中,我们将介绍C++ SDK核心接口的用法以及代码示例,以协助用户更快接入。
1. 创建客户端
第一步,需要创建客户端,默认客户端采用grpc协议,且为同步调用。
#include <iostream>
#include "proxima_searcher_client.h"
using proxima::be;
// 默认类型客户端
auto client = ProximaSearchClient::Create();
第二步,创建完客户端之后,我们需要显示连接ProximaBE服务:
// 设置连接参数,注意这里需要填写grpc协议监听端口
ChannelOptions options("127.0.0.1:16000");
// 连接服务端
Status status = client->connect(options);
if (status.code != 0) {
std::cerr << "Connect server failed." << std::endl;
return status.code;
}
我们在连接过程中,除了简单的测试rpc连通性之外,还会与server校验版本信息,确保兼容性。
客户端所有接口,都会返回Status,用户需要检查status.code是否正常,其结构如下:
struct Status {
/// 错误码,0代表成功,其它非0代表调用错误
int code;
/// 错误原因, 默认为"Success",否则是错误描述
std::string reason;
}
代码中涉及到其它结构以及字段,可以参见ChannelOptions
2. 集合管理
我们提供了Collection的创建、删除、查询、统计等接口,供用户方便的管理集合。
2.1. 创建Collection
创建一个名为Plants的集合,其中正排列为价格"price"以及描述"description",索引列为向量列,存储4维float类型
/// 描述Collection的具体格式
CollectionConfig config;
config.collection_name = "Plants";
config.forward_columns = {"Price", "Description"};
config.index_columns = {IndexColumnParam("ImageVector", DataType::VECTOR_FP32, 8)}
/// 创建Collection
Status status = client->create_collection(config);
if (status.code != 0) {
std::cerr << "Create collection failed." << std::endl;
return status.code;
}
集合配置详细信息请参考: CollectionConfig
2.2. 查询Collection
创建完集合之后,我们可以使用查询接口查看其状态。
/// 获取CollectionInfo
CollectionInfo collection_info;
Status status = client->describe_collection("Plants", &collection_info);
if (status.code != 0) {
std::cerr << "Get collection info failed." << std::endl;
return status.code;
}
/// 打印CollectionInfo
std::cout << collection_info.collection_name << std::endl;
std::cout << collection_info.collection_status << std::endl;
std::cout << collection_info.uuid << std::endl;
......
除此之外,我们还可以将所有Collection信息一次性列出来
/// 获取所有的Collection信息
std::vector<CollectionInfo> collection_infos;
Status status = client->list_collections(&collection_infos);
if (status.code != 0) {
std::cerr << "List collection infos failed." << std::endl;
return status.code;
}
返回的集合信息详细字段请参考: CollectionInfo
2.3. 统计Collection
Collection经过一段时间的读写之后,我们可以通过统计接口观察其装载的文档数据。
/// 获取CollectionStats
CollectionStats collection_stats;
Status status = client->stats_collection("Plants", &collection_stats);
if (status.code != 0) {
std::cerr << "Get collection statistics failed." << std::endl;
return status.code;
}
/// 打印CollectionStats
std::cout << collection_stats.collection_name << std::endl;
std::cout << collection_stats.total_doc_count << std::endl;
std::cout << collection_stats.total_segment_cout << std::endl;
.....
集合统计详细字段信息请参考: CollectionStats
2.4. 删除Collection
Collection完成其历史使命后,我们可以彻底删除掉某个collection。
/// 删除集合
Status status = client->drop_collection("Plants");
if (status.code != 0) {
std::cerr << "Drop collection failed." << std::endl;
return status.code;
}
3. 文档管理
对于某一个集合而言,我们提供增加、更新、删除文档的接口,同时支持批量模式。
3.1. 插入文档
我们在之前已经创建完成的名为"Plants"的集合中,插入100条数据
/// 创建一个写入请求
auto write_request = WriteRequest::Create();
/// 设置集合以及文档数据格式
write_request->set_collection_name("Plants");
write_request->add_forward_columns({"Price", "Description"});
write_request->add_index_column("ImageVector", DataType::VECTOR_FP32, 8);
/// 批量填充100条文档数据
for (int i = 0; i < 100; i++) {
auto row = write_request->add_row();
row->set_primary_key(i);
/// 设置为插入操作
row->set_operation_type(OperationType::INSERT);
row->add_forward_value((float)i + 0.1f);
row->add_forward_value("iris with number " + std::to_string(i));
row->add_index_value({i, i, i, i, i, i, i, i});
}
/// 写入到服务端
Status status = client->write(*write_request);
if (status.code != 0) {
std::cerr << "Write records failed." << std::endl;
return status.code;
}
在上述参考代码中,有几点值得注意:
-
设置文档数据格式。 这里最早其实在创建Collection时候,我们填写过一次,这里需要再次设置的主要原因有两个。 第一个是由于我们未来会支持实时量化的能力,可能用户配置的类型与输入类型不一致,使用我们动态转换的能力。第二个则是我们可以基于这个信息做二次校验,防止插入数据格式错误。
-
批量模式。 理论上在一个WriteRequest中我们可以组合任意多的文档,但由于会增大单个网络请求包大小,一般还是建议用户根据实际情况进行限制。
3.2. 更新文档
更新过程基本与插入过程一致,仅改变文档的操作类型即可。
.....
/// 批量更新100条文档数据
for (int i = 0; i < 100; i++) {
auto row = write_request->add_row();
row->set_primary_key(i);
/// 设置为更新操作
row->set_operation_type(OperationType::UPDATE);
row->add_forward_value((float)i + 0.2f);
row->add_forward_value("iris with number " + std::to_string(i));
row->add_index_value({i, i, i, i, i, i, i, i});
}
......
NOTE: 值得注意的是,目前我们实际实现中采取的是标记删除的模式,更新=删除+新增,而删除占比过高会极大影响查询性能,这一点用户务必注意。
写入请求的详细信息可以参考: WriteRequest
3.3. 删除文档
删除过程依然可以复用上述的代码结构,如果批量请求中没有插入、更新请求,那么代码可以极大简化。
/// 创建一个写入请求
auto write_request = WriteRequest::Create();
/// 设置集合以及文档数据格式
write_request->set_collection_name("Plants");
/// 批量删除100条文档数据
for (int i = 0; i < 100; i++) {
auto row = write_request->add_row();
/// 设置为删除操作,仅需要填写primary key即可
row->set_primary_key(i);
row->set_operation_type(OperationType::DELETE);
}
/// 发送到服务端
Status status = client->write(*write_request);
if (status.code != 0) {
std::cerr << "Write records failed." << std::endl;
return status.code;
}
NOTE: 值得注意的是,由于我们内部采用图索引结构,删除目前采取标记删除方式,删除比例过高会带来连通性问题,影响召回和性能。我们一般不建议用户删除超过50%的文档,否则查询性能将会弱化很多。
4. 文档查询
最后我们希望能够在创建的"Plants"集合中查询这100条数据,相似度召回10条结果。
auto query_request = QueryRequest::Create();
auto query_response = QueryResponse::Create();
/// 填充请求参数
query_request->set_collection_name("Plants");
auto knn_param = query_request->add_knn_query_param();
knn_param->set_column_name("ImageVector");
knn_param->set_topk(10);
knn_param->set_features({0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8});
/// Knn查询
Status status = client->query(*query_request, query_response.get());
if (status.code != 0) {
std::cerr << "Query records failed." << std::endl;
return status.code;
}
/// 打印结果
for (size_t i = 0; i < query_response->result_count(); i++) {
auto result = query_response->result(i);
for (size_t j = 0; j < result->document_count(); j++){
auto doc = result->document(j);
/// 获取文档的primary key和相似度距离
std::cout << doc->primary_key() << std::endl;
std::cout << doc->score() << std::endl;
/// 按顺序取正排字段
float price;
std::string desc;
doc->get_forward_value("Price", &price);
doc->get_forward_value("Description", &desc);
std::cout << price << std::endl;
std::cout << desc << std::endl;
}
}
我们query同样也可以支持批量模式
const *vector_bytes;
size_t vector_size;
......
auto knn_param = query_request->add_knn_query_param();
knn_param->set_column_name("ImageVector");
knn_param->set_topk(10);
knn_param->set_features(vector_bytes, vector_size, 100);
knn_param->set_data_type(DataType::VECTOR_FP32);
knn_param->set_dimension(8);
上述代码中描述了设置一段连续的bytes作为查询向量,包含100个连续的查询向量,其中每个为8维float类型。
NOTE: 还有一点值得注意的是,最终的正排数据的获取,必须按照CollectionConfig定义的顺序逐一获取,顺序不对或者类型不对,均会导致获取到空结果
上述参考代码中查询请求和查询结果的详细信息请参考: QueryRequest
5. 错误码
| 错误码 | 错误原因 | 备注 |
|---|---|---|
| 0~9999 | 服务端错误 | |
| 10000 | 初始化客户端失败 | |
| 10001 | RPC连接出错 | |
| 10002 | 客户端与服务端版本不匹配 | |
| 10003 | 客户端还未连接 | |
| 10004 | 请求校验失败 |
6. 接口&类型
ProximaSearchClient
/**
* ProximaSearchClient wrappers the operations used to call proxima search
* engine's service. Server may be running on another machines. It shields
* implementation of communication protocol and rpc details, and provide
* extremely high bench performance.
*
* Usage exp:
* auto client = ProximaSearchClient::Create();
* if (client != nullptr) {
* client->connect(ChannelOptions("127.0.0.1:16000"));
* ...
* client->create_collection();
* client->close();
* }
*
* Please read the examples/client_example.cc for more details.
*
* Note: the functions of this class are sync call.
*/
class ProximaSearchClient {
public:
/// @brief Create a client instance and return its shared ptr.
///
/// @param type Client type, only support "GrpcClient" now.
/// @return Shared ptr pointed to client impl.
///
/// @note If input type is wrong, it may return nullptr
static ProximaSearchClientPtr Create(const std::string &type);
//! Create a shared ptr of client with default type
static ProximaSearchClientPtr Create();
/// @brief Try to connect remote server and establish connection.
///
/// @param options Socket connection relative configs.
/// @return Status.code 0 means success, other means fail
///
/// @note This function will try to send a list collections command
/// to test if the server alive.
virtual Status connect(const ChannelOptions &options) = 0;
//! Close connection to remote server and cleanup self
virtual Status close() = 0;
/// @brief Create a collection with specific config.
///
/// @param config Collection config
/// @return Status.code 0 means success, other means fail
virtual Status create_collection(const CollectionConfig &config) = 0;
/// @brief Drop a collection with specific name.
///
/// @param collection_name Collection name
/// @return Status.code 0 means success, other means fail
virtual Status drop_collection(const std::string &collection_name) = 0;
/// @brief Show the detailed information of collection.
///
/// @param[in] collection_name Collection name
/// @param[out] collection_info Collection information
/// @return Status.code 0 means success, other means fail
virtual Status describe_collection(const std::string &collection_name,
CollectionInfo *collection_info) = 0;
/// @brief Get collection statics.
///
/// @param[in] collection_name Collection name
/// @param[out] stats Collection statistics struct
/// @return Status.code 0 means success, other means fail.
virtual Status stats_collection(const std::string &collection_name,
CollectionStats *stats) = 0;
/// @brief List all collections.
///
/// @param[out] collections Collection infomations
/// @return Status.code 0 means success, other means fail
virtual Status list_collections(std::vector<CollectionInfo> *collections) = 0;
/// @brief Insert/Update/Delete records.
///
/// @param request Write request
/// @return Status.code means success, other means fail
virtual Status write(const WriteRequest &request) = 0;
/// @brief Knn query similar results
///
/// @param[in] request Query request
/// @param[out] respnose Query response
/// @return Status.code means success, other means fail
virtual Status query(const QueryRequest &request,
QueryResponse *response) = 0;
/// @brief Get document by primary key
///
/// @param[in] request Get document request
/// @param[out] response Get document response
/// @return Status.code means success, other means fail
virtual Status get_document_by_key(const GetDocumentRequest &request,
GetDocumentResponse *response) = 0;
};
ChannelOptions
/**
* ChannelOptions represents the connection config.
*/
struct ChannelOptions {
/// Host name of proximabe server
/// For exapmle: "127.0.0.1:16000"
/// Required field
std::string host{};
/// Max rpc duration out over server
/// Optional field, default 1000
uint32_t timeout_ms{1000U};
/// Max retry times when rpc failed
/// Optional filed, default 3
uint32_t max_retry{3U};
/// Connection pool count
/// Optional filed, default 1
uint32_t connection_count{1};
ChannelOptions(const std::string &val) : host(val) {}
};
CollectionConfig
/**
* CollectionConfig describes the config options of collection.
* It includes description of index columns and forward columns.
* Index columns means that this column data is for knn searching.
* Forward columns means that this column data is just for display,
* which is not anticipating in search process.
*/
struct CollectionConfig {
/// Collection name, it should be unique
/// Required field
std::string collection_name{};
/// Collection will split into serveral segments
/// This param means max doc limits in one segment
/// Optional field, default 0, means no limit
uint32_t max_docs_per_segment{0U};
/// Forward column names
/// Optional field
std::vector<std::string> forward_columns{};
/// Index column infos
/// Required filed
std::vector<IndexColumnParam> index_columns{};
/// Database repository config
/// Optional field, default empty
DatabaseRepository database_repository{};
};
/**
* IndexColumnParam represents the index config of index column.
*/
struct IndexColumnParam {
/// Column name
/// Required field
std::string column_name{};
/// Column index type
/// Optional field, default IndexType::PROXIMA_GRAPH_INDEX
IndexType index_type{IndexType::PROXIMA_GRAPH_INDEX};
/// Stored data type
/// Optional filed, default DataType::VECTOR_FP32
DataType data_type{DataType::VECTOR_FP32};
/// Stored data dimension
/// Optional filed, default 0
uint32_t dimension{0U};
/// Extra params for column index
/// Optional field
/// For example:
/// {"ef_construction": "400", "ef_search": "300"}
std::vector<KVPair> extra_params{};
IndexColumnParam() = default;
IndexColumnParam(const std::string &val1, DataType val2, uint32_t val3)
: column_name(val1), data_type(val2), dimension(val3) {}
};
CollectionInfo
/**
* CollectionInfo describes the detailed information of collection,
* which is ProximaSE server returned.
*/
struct CollectionInfo {
enum class CollectionStatus : uint32_t {
INITIALIZED = 0,
SERVING = 1,
DRPPED = 2
};
//! Collection name
std::string collection_name{};
//! Collection status
CollectionStatus collection_status{CollectionStatus::INITIALIZED};
//! Unique uuid to a collection
std::string collection_uuid{};
//! Latest record's log sequence number
uint64_t latest_lsn{0U};
//! Latest record's lsn context
std::string latest_lsn_context{};
//! Server magic number, generally is server started timestamp
uint64_t magic_number{0U};
//! Collection's config max doc number per segment
uint32_t max_docs_per_segment{0U};
//! Collection's forward column names
std::vector<std::string> forward_columns{};
//! Collection's index column params
std::vector<IndexColumnParam> index_columns{};
//! Collection's database repository information
DatabaseRepository database_repository{};
};
CollectionStats
/**
* CollectionStats describes the detailed stastistics of collection
*/
struct CollectionStats {
/**
* Segment state
*/
enum class SegmentState : uint32_t {
CREATED = 0,
WRITING = 1,
DUMPING = 2,
COMPACTING = 3,
PERSIST = 4
};
/*
* SegmentStats describes the detailed stastistics of segment
*/
struct SegmentStats {
//! Segment unique id
uint64_t segment_id{0U};
//! Segment state
SegmentState segment_state{SegmentState::CREATED};
//! Document count in this segment
uint64_t doc_count{0U};
//! Index file count of this segment
uint64_t index_file_count{0U};
//! Totaol index file size
uint64_t index_file_size{0U};
//! Min document id
uint64_t min_doc_id{0U};
//! Max document id
uint64_t max_doc_id{0U};
//! Min primary key value of the segment
uint64_t min_primary_key{0U};
//! Min primary key value of the segment
uint64_t max_primary_key{0U};
//! Earliest record timestamp
uint64_t min_timestamp{0U};
//! Last record timestamp
uint64_t max_timestamp{0U};
//! Minimal log sequence number
uint64_t min_lsn{0U};
//! Maximum log sequence number
uint64_t max_lsn{0U};
};
//! Collection name
std::string collection_name{};
//! Total document count of this collection
uint64_t total_doc_count{0U};
//! Total segment count of this collectoin
uint64_t total_segment_count{0U};
//! Total index file count
uint64_t total_index_file_count{0U};
//! Total index file size
uint64_t total_index_file_size{0U};
//! Detailed segment stastistics
std::vector<SegmentStats> segment_stats{};
};
WriteRequest
/**
* WriteRequest shows how to wrapper write request data fields.
*
* Usage exp:
* WriteRequestPtr request = WriteRequest::Create();
* request->set_collection_name("test_collection");
* request->set_row_meta({"test_column"}, {});
* auto row = request->add_row();
* row->set_primary_key = 123;
* row->set_operation_type(OperationType::OP_INSERT);
* row->add_index_value({0.1, 0.2, 0.3});
* ...
* client->write(*request);
*/
class WriteRequest {
public:
/**
* A row describes the format of one record
*/
class Row {
public:
//! Set primary key, required
virtual void set_primary_key(uint64_t val) = 0;
//! Set operation type, optional, default DataType::INSERT
virtual void set_operation_type(OperationType op_type) = 0;
//! Set lsn, optional, default 0
virtual void set_lsn(uint64_t lsn) = 0;
//! Set lsn context, optional, default ""
virtual void set_lsn_context(const std::string &lsn_context) = 0;
/// @brief Add forward value with string type
///
/// @note Add forward value sort must match configured
/// forward columns in CollectionConfig
virtual void add_forward_value(const std::string &val) = 0;
//! Add forward value with bool type
virtual void add_forward_value(bool val) = 0;
//! Add forward value with int32 type
virtual void add_forward_value(int32_t val) = 0;
//! Add forward value with int64 type
virtual void add_forward_value(int64_t val) = 0;
//! Add forward value with uint32 type
virtual void add_forward_value(uint32_t val) = 0;
//! Add forward value with uint64 type
virtual void add_forward_value(uint64_t val) = 0;
//! Add forward value with float type
virtual void add_forward_value(float val) = 0;
//! Add forward value with double type
virtual void add_forward_value(double val) = 0;
/// @brief Add index value, vector bytes type
///
/// @note Add index value sort must match configured
/// index columns in CollectionConfig
virtual void add_index_value(const void *val, size_t val_len) = 0;
//! Add index value, vector array type
virtual void add_index_value(const std::vector<float> &val) = 0;
/// Add index value by json format
/// Two json format:
/// "[0.1, 0.2, 0.3, 0.4]"
/// "[[0.1, 0.2, 0.3, 0.4], [0.5, 0.6, 0.7, 0.8]]"
virtual void add_index_value_by_json(const std::string &json_val) = 0;
};
using RowPtr = std::shared_ptr<Row>;
public:
//! Constructor
static WriteRequestPtr Create();
//! Set collection name, required, must be unique
virtual void set_collection_name(const std::string &val) = 0;
/// @brief Add forward column in row meta
/// @note Forward column names' sort must match configured
/// forward columns in CollectionConfig
virtual void add_forward_column(const std::string &column_name) = 0;
/// @brief Add forward columns in row meta
/// @note Forward column names' sort must match configured
/// forward columns in CollectionConfig
virtual void add_forward_columns(
const std::vector<std::string> &column_names) = 0;
/// @brief Add index column in row meta
///
/// @param column_name Column name
/// @param data_type Send data type
/// @param dimension Send data dimension
///
/// @note Index column names' sort must match configured
/// index columns in CollectionConfig
virtual void add_index_column(const std::string &column_name,
DataType data_type, uint32_t dimension) = 0;
//! Add row data, required, can't send empty request
virtual WriteRequest::RowPtr add_row() = 0;
//! Set request id for tracelog, optional
virtual void set_request_id(const std::string &request_id) = 0;
//! Set magic number for validation, optional
virtual void set_magic_number(uint64_t magic_number) = 0;
};
QueryRequest
/**
* QueryRequest shows how to wrapper query data fields.
*
* Usage exp:
* QueryRequestPtr request = QueryRequest::Create();
* request->set_collection_name("test_colletion");
* auto knn_param = request->add_knn_query_param();
* knn_param->set_column_name("test_column");
* knn_param->set_features({0.1, 0.2, 0.3, 0.4});
* knn_param->set_batch_count(1);
* knn_param->set_dimension(4);
* knn_param->set_data_type(DT_VECTOR_FP32);
* ...
*
*/
class QueryRequest {
public:
/**
* KnnQueryParam describes the options of knn query
*/
class KnnQueryParam {
public:
//! Set column name, required
virtual void set_column_name(const std::string &val) = 0;
//! Set topk, required
virtual void set_topk(uint32_t val) = 0;
/// Set query vector with bytes format by single
/// Required set
virtual void set_features(const void *val, size_t val_len) = 0;
//! Set features with vector array format by single
virtual void set_features(const std::vector<float> &val) = 0;
//! Set query vector with bytes format by batch
virtual void set_features(const void *val, size_t val_len,
uint32_t batch) = 0;
/// Set features by json format
/// Two json format:
/// "[0.1, 0.2, 0.3, 0.4]"
/// "[[0.1, 0.2, 0.3, 0.4], [0.5, 0.6, 0.7, 0.8]]"
virtual void set_features_by_json(const std::string &json_val) = 0;
//! Set features by json format and by batch
virtual void set_features_by_json(const std::string &json_val,
uint32_t batch) = 0;
//! Set vector data dimension, required
virtual void set_dimension(uint32_t val) = 0;
//! Set vector data type, required
virtual void set_data_type(DataType val) = 0;
//! Set search radius, optional, default 0.0f not open
virtual void set_radius(float val) = 0;
//! Set if use linear search, optional, default false
virtual void set_linear(bool val) = 0;
//! Add extra params, like ef_search ..etc, optional
virtual void add_extra_param(const std::string &key,
const std::string &val) = 0;
};
using KnnQueryParamPtr = std::shared_ptr<KnnQueryParam>;
public:
//! Constructor
static QueryRequestPtr Create();
//! Set collection name, required
virtual void set_collection_name(const std::string &val) = 0;
//! Set knn query param, required
virtual QueryRequest::KnnQueryParamPtr add_knn_query_param() = 0;
//! Set debug mode, optional, default false
virtual void set_debug_mode(bool val) = 0;
};
QueryResponse
/**
* QueryResponse shows the format of query response.
*/
class QueryResponse {
public:
/**
* Result represents a knn query's result
*/
class Result {
public:
//! Return document count
virtual size_t document_count() const = 0;
//! Return document pointer of specific pos
virtual DocumentPtr document(int index) const = 0;
};
public:
//! Constructor
static QueryResponsePtr Create();
//! Return debug info
virtual const std::string &debug_info() const = 0;
//! Return query latency, microseconds
virtual uint64_t latency_us() const = 0;
//! Return batch result count
virtual size_t result_count() const = 0;
//! Return result pointer of specific batch pos
virtual QueryResponse::ResultPtr result(int index) const = 0;
};
/**
* Document shows the format of knn query response
*/
class Document {
public:
//! Return document primary key
virtual uint64_t primary_key() const = 0;
//! Return calculated knn distance score
virtual float score() const = 0;
//! Return forward values count
virtual size_t forward_count() const = 0;
//! Get forward names
virtual void get_forward_names(
std::vector<std::string> *forward_names) const = 0;
//! Get forward value with string type
virtual void get_forward_value(const std::string &key,
std::string *val) const = 0;
//! Get forward value with bool type
virtual void get_forward_value(const std::string &key, bool *val) const = 0;
//! Get forward value with int32 type
virtual void get_forward_value(const std::string &key,
int32_t *val) const = 0;
//! Get forward value with int64 type
virtual void get_forward_value(const std::string &key,
int64_t *val) const = 0;
//! Get forward value with uint32 type
virtual void get_forward_value(const std::string &key,
uint32_t *val) const = 0;
//! Get forward value with uint64 type
virtual void get_forward_value(const std::string &key,
uint64_t *val) const = 0;
//! Get forward value with float type
virtual void get_forward_value(const std::string &key, float *val) const = 0;
//! Get forward value with double type
virtual void get_forward_value(const std::string &key, double *val) const = 0;
};
5.3 - Java SDK
本文主要介绍用户如何使用 Java SDK,来进行集合管理、文档的增删改查等功能。
1. 前提条件
使用 ProximaBE 的 Java SDK,必须满足以下两点:
- JDK 1.8 或者以上版本
- 使用 Apache Maven
2. 安装 Java SDK
可以通过Apache Maven二方库依赖的方式,将 SDK 下载到自己的项目中。
<dependency>
<groupId>com.alibaba.proxima</groupId>
<artifactId>proxima-be-java-sdk</artifactId>
<version>0.1.2-SNAPSHOT</version>
</dependency>
3. 客户端创建
ProximaSearchClient 是ProximaBE 对外的所有接口的代理层,用户通过传入连接参数,创建该客户端对象,就可以对 ProximaBE 中的集合进行相关的操作。
3.1. 初始化连接参数
构建类:ConnectParam.Builder
首先通过调用 ConnectParam 的 newBuilder 接口,创建出 ConnectParam 的 Builder 对象,然后依次通过Builder对象设置 ProximaBE 的 host 地址,以及 grpc 端口等信息,最终调用 Builder的 build 接口,即可构建出 ConnectParam 对象。
Builder 参数说明:
| 参数 | 说明 |
|---|---|
| host | ProximaBE对应的服务地址,String类型默认为 localhost |
| port | ProximaBE对应的GRPC服务端口,int类型,默认16000 |
| IdleTimeout | GRPC链接空闲的超时时间,long类型,默认12小时 |
3.2. 创建客户端对象
接口:ProximaGrpcSearchClient(ConnectParam connectParam)
通过传入的 connectParam 对象创建 ProximaBE 客户端,目前支持 Grpc 协议,创建成功后返回 ProximaSearchClient 对象,目前 Client 中的接口均为同步接口。
参数说明:
- ConnectParam:表示连接 ProximaBE 所需要的相关连接参数信息
3.3. 示例
创建 ProximaSearchClient 对象
import com.alibaba.proxima.se.client.*;
// init connect params
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost("127.0.0.1")
.withPort(16000)
.build();
// create client
ProximaSearchClient client = new ProximaGrpcSearchClient(connectParam);
4. 集合管理
集合管理主要包括集合的创建、集合的查询和集合的删除等操作。
4.1. 创建集合
4.1.1 创建 CollectionConfig
构造类:CollectionConfig.Builder
首先通过调用 CollectionConfig 的 newBuilder 接口,创建出 CollectionConfig 的 Builder 对象,然后通过 Builder 对象设置集合名称、索引列信息、正排列信息等,最终调用 Builder 的 build 接口,即可构建出 CollectionConfig 对象。
Builder 参数说明:
| 参数 | 说明 |
|---|---|
| collectionName | 集合的名称,String类型 |
| indexColumnParams | 索引列参数列表,List |
| forwardColumnNames | 正排列的名称列表,List |
| maxDocsPerSegment | 分片最大文档数,long类型,默认值为0,表示不限制单片文档数 |
| databaseRepository | 数据库源相关配置,如果是数据库旁路集合,需要配置该选项,目前只支持 mysql 数据库 |
IndexColumnParam 参数:
| 参数 | 说明 |
|---|---|
| columnName | 索引列名称,String 类型 |
| indexType | 索引类型,IndexType 类型,目前支持 PROXIMA_GRAPH_INDEX 类型索引 |
| dataType | 索引列数据类型,DataType 类型 |
| dimension | 索引的维度,int 类型 |
| extraParams | 其它的参数,Map类型 |
4.1.2 调用创建接口
接口: Status createCollection(CollectionConfig collectionConfig)
根据参数 CollectionConfig 对象创建集合,返回值为 Status 对象,表示集合创建成功与否,如果传入的 CollectionConfig 对象非法,会抛出 ProximaBEException 异常。
参数说明:
- collectionConfig:其中包含了集合的基础配置信息,主要有集合名称、索引列信息、正排列名称列表等。
返回值:
- Status:表示创建成功与否,其中包含错误码和错误描述
4.1.3 示例
示例 1:创建一个带有两个正排列,以及单个向量索引列的集合
public boolean createCollection(ProximaSearchClient client) {
String collectionName = "collection1";
int dimension = 8;
// create collection builder
CollectionConfig config = CollectionConfig.newBuilder()
.withCollectionName(collectionName) // set collection name
.withForwardColumnNames(Arrays.asList("forward1", "forward2")) // set forward column names
.addIndexColumnParam("index1", DataType.VECTOR_FP32, dimension)// add one index column param
.build(); // build the CollectionConfig
// call create collection interface
try {
Status status = client.createCollection(config);
if (status.ok()) {
System.out.println("============== Create collection success. ================");
return true;
} else {
System.out.println("Create collection failed." + status.toString());
return false;
}
} catch (ProximaBEException e) {
e.printStackTrace();
return false;
}
}
示例 2:创建一个带有两个正排列、单个向量索引列、以及作为Mysql 数据旁路的集合
public boolean createCollectionWithRepo(ProximaSearchClient client) {
String collectionName = "collection2";
int dimension = 8;
// create database repository
DatabaseRepository repo = DatabaseRepository.newBuilder()
.withConnectionUri("mysql://host.com:8080/mysql_database") // set connection uri
.withTableName("mysql_table1") // set table name
.withRepositoryName("mysql_repo") // set repository name
.withUser("root") // set user name
.withPassword("root") // set password
.build();
// create collection builder
CollectionConfig config = CollectionConfig.newBuilder()
.withCollectionName(collectionName) // set collection name
.withForwardColumnNames(Arrays.asList("forward1", "forward2")) // set forward column name list
.addIndexColumnParam("index1", DataType.VECTOR_FP32, dimension)// add one index column param
.withDatabaseRepository(repo) // set database repoistory
.build();
// call create collection interface
try {
Status status = client.createCollection(config);
if (status.ok()) {
System.out.println("============== Create collection success. ================");
return true;
} else {
System.out.println("Create collection failed." + status.toString());
return false;
}
} catch (ProximaBEException e) {
e.printStackTrace();
return false;
}
}
4.2. 查询集合配置信息
接口: DescribeCollectionResponse describeCollection(String collectionName)
根据传入的集合名称,获取当前集合对应的相关配置信息。
参数说明:
- collectionName:集合名称
返回值:
- DescribeCollectionResponse:其中包含 Status 以及 CollectionInfo 两部分,Status 描述当前请求成功与否,CollectionInfo 描述集合的配置信息
示例:
查询 collection 的配置信息
public boolean describeCollection(ProximaSearchClient client) {
String collectionName = "collection1";
// describe collection
DescribeCollectionResponse descResponse = client.describeCollection(collectionName);
if (descResponse.ok()) {
System.out.println("================ Describe collection success. ===================");
CollectionInfo info = descResponse.getCollectionInfo();
CollectionConfig collectionConfig = info.getCollectionConfig();
System.out.println("CollectionName: " + collectionConfig.getCollectionName());
System.out.println("CollectionStatus: " + info.getCollectionStatus());
System.out.println("Uuid: " + info.getUuid());
System.out.println("Forward columns: " + collectionConfig.getForwardColumnNames());
List<IndexColumnParam> indexColumnParamList = collectionConfig.getIndexColumnParams();
for (int i = 0; i < indexColumnParamList.size(); ++i) {
IndexColumnParam indexParam = indexColumnParamList.get(i);
System.out.println("IndexColumn: " + indexParam.getColumnName());
System.out.println("IndexType: " + indexParam.getDataType());
System.out.println("DataType: " + indexParam.getDataType());
System.out.println("Dimension: " + indexParam.getDimension());
}
return true;
} else {
System.out.println("Describe collection failed " + descResponse.toString());
return false;
}
}
4.3. 查询集合统计信息
接口: StatsCollectionResponse statsCollection(String collectionName)
根据传入的集合名称,获取当前集合对应的相关统计信息。
参数说明:
- collectionName:集合名称
返回值:
- StatsCollectionResponse:其中包含 Status 以及 CollectionStats 两部分,Status 描述当前请求成功与否,CollectionStats 描述集合的相关统计信息,包含的信息如下:
| 字段名称 | 说明 |
|---|---|
| collectionPath | collection 的索引路径 |
| totalDocCount | 总的文档数量 |
| totalSegmentCount | 总的segment数量 |
| totalIndexFileCount | 总的索引文件数量 |
| totalIndexFileSize | 总的索引文件大小 |
| segmentStatsList | 每个 segment 相应的统计信息,包括 segment 的总文档数量、索 引文件数量和大小,以及最大/小 doc id等 |
示例 :
查询指定集合的统计信息
public boolean statsCollection(ProximaSearchClient client) {
String collectionName = "collection1";
// call stats collection interface
StatsCollectionResponse statsResponse = client.statsCollection(collectionName);
if (statsResponse.ok()) {
System.out.println("==================== Stats collection success. ======================");
CollectionStats stats = statsResponse.getCollectionStats();
System.out.println("CollectionName: " + stats.getCollectionName());
System.out.println("TotalDocCount: " + stats.getTotalDocCount());
System.out.println("TotalSegmentCount: " + stats.getTotalSegmentCount());
for (int i = 0; i < stats.getSegmentStatsCount(); ++i) {
System.out.println("Segment: " + i);
System.out.println("SegmentDocCount: " + stats.getSegmentStats(i).getDocDount());
System.out.println("SegmentIndexFileCount: " + stats.getSegmentStats(i).getIndexFileCount());
System.out.println("SegmentMaxDocId: " + stats.getSegmentStats(i).getMaxDocId());
}
return true;
} else {
System.out.println("Stats collection failed " + statsResponse.getStatus().toString());
return false;
}
}
4.4. 删除集合
接口: Status dropCollection(String collectionName)
删除指定集合,集合名由参数 collectionName 指定
参数说明:
- collectionName:删除的集合名称
返回值:
- Status:表示删除成功与否,其中包含错误码和错误描述
示例 :
删除指定集合
public boolean dropCollection(ProximaSearchClient client) {
String collectionName = "collection1";
// call drop collection interface
Status status = client.dropCollection(collectionName);
if (status.ok()) {
System.out.println("==================== Dorp collection success. ========================");
return true;
} else {
System.out.println("Drop collection failed " + status.toString());
return false;
}
}
4.5. 获取集合列表
接口: ListCollectionsResponse listCollections(ListCondition listCondition)
根据传入的 ListCondition 条件获取满足条件的集合列表
参数说明:
- listCondition:集合需要满足的条件,目前只包含了一个 Repository 名称字段,仅用在Mysql 同步数据时,如果该字段为空或者 listCondition 为空时,返回所有的集合
返回值:
- ListCollectionsResponse:包含 Status 和 CollectionInfo List 两部分,前者描述请求是否成功,后者描述所有集合的配置信息。
示例 :
获取 repository name 为 mysql_repo 的所有集合
public boolean listCollections(ProximaSearchClient client) {
// build list condition object
ListCondition listCondition = ListCondition.newBuilder()
.withRepositoryName("mysql_repo") // set repository name
.build();
// call list collections interface
ListCollectionsResponse listResponse = client.listCollections(listCondition);
if (listResponse.ok()) {
System.out.println("List collections success.");
for (int i = 0; i < listResponse.getCollectionCount(); ++i) {
System.out.println("Collection " + i);
CollectionInfo info = listResponse.getCollection(i);
CollectionConfig collectionConfig = info.getCollectionConfig();
System.out.println("CollectionName: " + collectionConfig.getCollectionName());
System.out.println("CollectionStatus: " + info.getCollectionStatus());
System.out.println("Uuid: " + info.getUuid());
System.out.println("Forward columns: " + collectionConfig.getForwardColumnNames());
List<IndexColumnParam> indexColumnParamList = collectionConfig.getIndexColumnParams();
for (int j = 0; j < indexColumnParamList.size(); ++j) {
IndexColumnParam indexParam = indexColumnParamList.get(j);
System.out.println("IndexColumn: " + indexParam.getColumnName());
System.out.println("IndexType: " + indexParam.getDataType());
System.out.println("DataType: " + indexParam.getDataType());
System.out.println("Dimension: " + indexParam.getDimension());
}
}
return true;
} else {
System.out.println("List collections failed " + listResponse.toString());
return false;
}
}
5. 文档管理
文档管理主要包括文档的插入、更新和删除操作,ProximaBE 中将文档的这三种操作,整合为一个通用的 Write 接口,通过一个 WriteRequest 结构来描述相关的操作,WriteRequest 中既可以描述单条记录的操作,也可以描述批量记录的操作。
5.1. 创建 WriteRequest
构造类:WriteRequest.Builder
首先通过 WriteRequest 的 newBuilder() 接口创建出 WriteRequest 的 Builder 对象,然后通过 Builder 对象设置相关参数,包括集合名称、正排列和索引列,以及 Rows等信息,最终调用 Builder 的 build 接口创建出 WriteRequest 对象。
参数说明:
| 参数 | 说明 |
|---|---|
| collectionName | 集合名称,String类型 |
| forwardColumnList | 正排列的名称列表,List类型,插入和更新时必须要设置,删除时不需要设置 |
| indexColumnMetaList | 索引列的 Meta 列表,插入和更新时必须要设置,删除时不需要设置 |
| rows | 请求中包含的文档操作列表,List类型,每一个 row 表示一个文档操作,具体内容见 Rows 参数说明 |
| requestId | 请求的 id,String类型,默认为空 |
| magicNumber | 请求中的魔数,long类型,仅在通过 Mysql 作为数据源时需要设置 |
Row 参数说明
| 参数 | 说明 |
|---|---|
| primaryKey | row的主键,long类型 |
| operationType | row的操作类型,候选值为 INSERT、UPDATE、DELETE三种 |
| indexValues | 对应索引列的值列表,List类型,operationType为DELETE操作时,不需要指定,支持三种格式:
|
| forwardValues | 对应正排列的值列表,List类型,operationType为DELETE时,不需要指定 |
| lsnContext | mysql 的 lsn 信息,仅当用 mysql 做数据同步时需要 |
5.2. 执行写入
接口: Status write(WriteRequest request)
向 ProximaBE 中写入文档操作请求,执行完成后返回 Status,表示执行成功与否,如果传入的 WriteRequest 请求非法,会抛出 ProximaBEException 异常。
参数说明:
- request:包含某个集合的插入、更新和删除等文档操作
返回值:
- Status:表示写入请求的成功与否
5.3. 示例
示例1:向集合 collection1 中分别插入和更新一条记录
public boolean write1(ProximaSearchClient client) {
String collectionName = "collection1";
float[] vectors1 = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f};
float[] vectors2 = {1.5f, 2.5f, 3.5f, 4.5f, 5.5f, 6.5f, 7.5f, 8.5f};
int dimension = 8;
long primaryKey = 123456;
int forward1Value = 123;
float forward2Value = 100.123f;
// build insert row
WriteRequest.Row insertRow = WriteRequest.Row.newBuilder()
.withPrimaryKey(primaryKey) // set primary key
.withOperationType(WriteRequest.OperationType.INSERT) // set operation type
.addIndexValue(vectors1) // add one index value
.addForwardValue(forward1Value) // add one forard value
.addForwardValue(forward2Value) // add one forward value
.build();
// build update row
WriteRequest.Row updateRow = WriteRequest.Row.newBuilder()
.withPrimaryKey(primaryKey) // set primary key
.withOperationType(WriteRequest.OperationType.UPDATE) // set operation type
.addIndexValue(vectors2) // add index value
.addForwardValue(forward1Value) // add forward value
.addForwardValue(forward2Value) // add forward value
.build();
// build delete row
long deleteKey = 10000;
WriteRequest.Row deleteRow = WriteRequest.Row.newBuilder()
.withPrimaryKey(deleteKey) // set primary key
.withOperationType(WriteRequest.OperationType.DELETE) // set operation type
.build();
// build write request
WriteRequest writeRequest = WriteRequest.newBuilder()
.withCollectionName(collectionName) // set collection name
.withForwardColumnList(Arrays.asList("forward1", "forward2")) // set forward column list
.addIndexColumnMeta("index1", DataType.VECTOR_FP32, dimension) // add one index column meta, otherwise call withIndexColumnMetaList
.addRow(insertRow) // add insert row
.addRow(updateRow) // add update row
.addRow(deleteRow) // add delete row
.build();
try {
// call write interface
Status status = client.write(writeRequest);
if (status.ok()) {
System.out.println("============== Write success. ===============");
return true;
} else {
System.out.println("Write failed " + status.toString());
return false;
}
} catch (ProximaBEException e) {
e.printStackTrace();
return false;
}*/
}
示例2:向集合 collection1 中删除一条记录
public boolean write2(ProximaSearchClient client) {
String collectionName = "collection1";
// build delete row
long deleteKey = 123456;
WriteRequest.Row deleteRow = WriteRequest.Row.newBuilder()
.withPrimaryKey(deleteKey) // set primary key
.withOperationType(WriteRequest.OperationType.DELETE) // set operation type
.build();
// build write request
WriteRequest writeRequest = WriteRequest.newBuilder()
.withCollectionName(collectionName) // set collection name
.addRow(deleteRow) // add delete row
.build();
try {
// call write interface
Status status = client.write(writeRequest);
if (status.ok()) {
System.out.println("============== Write success. ===============");
return true;
} else {
System.out.println("Write failed " + status.toString());
return false;
}
} catch (ProximaBEException e) {
e.printStackTrace();
return false;
}*/
}
6. 文档查询
文档查询目前主要包括两种类型,一种是根据向量来进行 knn 的查询,另一种是直接根据文档的主键来查询相应的文档。
6.1. 向量查询
6.1.1 创建 QueryRequest
构造类:QueryRequest.Builder
通过 QueryRequest 的 newBuilder 接口创建出 QueryRequest 的 Builder 对象,然后通过 Builder 对象设置相关查询参数,主要包括集合名称和 KnnQueryParam等参数,最终调用 Builder 的 build 接口构建出 QueryRequest 对象。
参数说明:
| 参数 | 说明 |
|---|---|
| collectionName | 要查询的集合名称,String类型 |
| knnQueryParam | knn 查询的参数,KnnQueryParam类型,具体内容见下表 |
| debugMode | 是否开启调试模式,boolean类型,默认为false |
KnnQueryParam 参数
| 参数 | 说明 |
|---|---|
| columnName | 要查询的索引列名,String类型 |
| topk | 查询的结果数量,int类型,默认为100 |
| features | 查询的特征,可以是单个或者多个向量,支持三种类型:
|
| dataType | 查询向量的数据类型,向量列表类型的特征支持自动推导,其它类型的必须设置 |
| dimension | 查询向量的维度,向量列表类型的特征支持自动推导,其它类型的必须设置 |
| batchCount | 查询的batch数量,向量列表类型的特征支持自动推导,其它类型的必须设置 |
| radius | 过滤结果的分数阈值,仅当分数小于该阈值的结果会返回,float类型,默认值为0,表示不过滤 |
| isLinear | 是否使用暴力检索,boolean类型,默认false |
6.1.2 执行查询
接口: QueryResponse query(QueryRequest request)
通过调用上述接口,向 ProximaBE 发起查询请求,返回 QueryResponse,当传入的 QueryRequest 非法时,会抛出 ProximaBEException 异常。
参数说明:
- request:表示查询请求,包含查询的集合以及查询的向量等信息
返回值:
- QueryResponse:表示查询的返回结果,包含查询的状态信息,以及查询的文档结果。
6.1.3. 示例
根据某个向量查询最相似的文档
public boolean query(ProximaSearchClient client) {
String collectionName = "collection1";
float[] features = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f};
// when batch querying, features can be following:
// float[][] features = {
// {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f},
// {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f}
// };
// build query request
QueryRequest queryRequest = QueryRequest.newBuilder()
.withCollectionName(collectionName) // set collection name
.withKnnQueryParam( // set knn query param
QueryRequest.KnnQueryParam.newBuilder() // new KnnQueryParam builder
.withColumnName("index1") // set index column name
.withTopk(10) // set topk
.withFeatures(features) // set query features
.build()) // build knnQueryParam object
.build(); // build query request
QueryResponse queryResponse = null;
try {
// call query interface
queryResponse = client.query(queryRequest);
} catch (ProximaBEException e) {
e.printStackTrace();
return false;
}
if (queryResponse.ok()) {
System.out.println("================ Query success =====================");
for (int i = 0; i < queryResponse.getQueryResultCount(); ++i) {
QueryResult queryResult = queryResponse.getQueryResult(i);
for (int d = 0; d < queryResult.getDocumentCount(); ++d) {
Document document = queryResult.getDocument(d);
System.out.println("Doc key: " + document.getPrimaryKey());
System.out.println("Doc score: " + document.getScore());
Set<String> forwardKeys = document.getForwardKeySet();
for (String forwardKey : forwardKeys) {
System.out.println("Doc forward: " + forwardKey + " -> " +
document.getForwardValue(forwardKey).getStringValue());
}
}
}
return true;
} else {
System.out.println("Query failed: " + queryResponse.getStatus().toString());
return false;
}
}
6.2. 主键查询
6.2.1 创建 GetDocumentRequest
构造类:GetDocumentRequest.Builder
通过 GetDocumentRequest 的 newBuilder 接口,创建出 GetDocumentRequest 的 Builder 对象,然后通过 Builder 对象设置相关查询参数,主要包括集合名称和 主键等参数,最终调用 Builder 的 build 接口构建出 GetDocumentRequest 对象。
Builder 参数说明:
| 参数 | 说明 |
|---|---|
| collectionName | 要查询的集合名称,String类型 |
| primaryKey | 要查询的文档的主键,long类型 |
| debugMode | 是否开启调试模式, boolean类型,默认为false |
6.2.2 执行查询
接口: GetDocumentResponse getDocumentByKey(GetDocumentRequest request)
通过调用上述接口,向 ProximaBE 发起查询请求,返回 GetDocumentResponse 对象,当传入的 GetDocumentRequest 非法时,会抛出 ProximaBEException 异常。
参数说明:
- request:表示查询指定文档请求
返回值:
- GetDocumentResponse:表示查询的返回结果,包含查询的状态信息,以及查询文档的结果。
6.2.3 示例
public boolean getDocument(ProximaSearchClient client) {
String collectionName = "collection1";
// build get document request
GetDocumentRequest getRequest = GetDocumentRequest.newBuilder()
.withCollectionName(collectionName) // set collection name
.withPrimaryKey(123456) // set primary key
.withDebugMode(true) // set debug mode, defalut false
.build(); // build GetDocumentRequest object
GetDocumentResponse getResponse = null;
try {
// call get document by key interface
getResponse = client.getDocumentByKey(getRequest);
} catch (ProximaBEException e) {
e.printStackTrace();
return false;
}
if (getResponse.ok()) {
System.out.println("======================== Get Document success ======================== ");
Document document = getResponse.getDocument();
System.out.println("PrimaryKey: " + document.getPrimaryKey());
System.out.println("Score: " + document.getScore());
Set<String> forwardKeys = document.getForwardKeySet();
for (String forwardKey : forwardKeys) {
System.out.println("Doc forward: " + forwardKey + " -> " +
document.getForwardValue(forwardKey).getStringValue());
}
System.out.println("DebugInfo: " + getResponse.getDebugInfo());
return true;
} else {
System.out.println("Get document failed " + getResponse.getStatus().toString());
return false;
}
}
5.4 - Golang SDK
用户可以使用Golang SDK进行集合管理、文档的增删该查等功能
1. BE客户端创建
ProximaSearchClient 是BE的客户端接口对象,用户通过该实例对象与BE进行交互,完成的管控功能
1.1. 创建客户端
NewProximaSearchClient(ConnectionProtocol, *Address) (ProximaSearchClient, error)
创建BE客户端,创建成功后返回ProximaSearchClient对象, 否则返回error。
参数说明:
- ConnectionProtocol: 与BE交互的协议类型,目前支持GRPC、HTTP两种协议,其中GRPC在性能以及资源占用上有明显的优势。
- *Address: 该参数指定BE的网络连接信息,主要包含BE的域名,以及端口号,详细定义如下:
// Address reference to entrypoint of ProximaBE
type Address struct {
// Host IP address or host name
Host string `json:"host:omitempty"`
// Port
Port uint32 `json:"port"`
}
返回值:
- ProximaSearchClient: BE客户端对象
- error: 执行错误时返回非nil
特殊说明:
- SDK中已封装了与BE通信的协议类型,如想进一步了解协议内容,请参考Restful API章节
示例: 创建BE客户端
package main
import (
"log"
"proxima-be-sdk-go/proxima/se/sdk"
)
func main() {
// Create client of BE with GRPC protocol and connect to localhost:16000
client, err := sdk.NewProximaSearchClient(sdk.GrpcProtocol, &sdk.Address{
Host: "localhost",
Port: 16000,
})
if err != nil {
log.Fatal("Can't create ProximaClient instance.", err)
}
}
2. 集合管理
2.1. 集合创建
CreateCollection(config *CollectionConfig) error
根据参数创建集合,创建成功后返回nil, 否则返回error。
参数说明:
- config: CollectionConfig中指定了集合的配置信息,包含不仅限于集合名、分片配置、正排列名、索引列信息等,当BE作为Mysql的从属库时,需指定Mysql Repo的相关配置,详情如示例。
返回值:
- error: 正常执行返回nil, 否则返回有效error对象
示例 1.1: 创建一个带有两个正排列,以及两个向量索引列的集合
fun createCollctionDemo(client *ProximaSearchClient) {
// Create collection with no attached repository
config := &sdk.CollectionConfig{
CollectionName: "example",
MaxDocsPerSegment: 0, // 0 means unlimited, which is equal max value of system
ForwardColumns: []string{"forward", "forward1"},
Columns: []sdk.ColumnIndex{
{
Name: "column",
IndexType: 0, // 0 means default index, which is sdk.ProximaGraphIndex
DataType: 0, // 0 means default, which is sdk.VectorFP32
Dimension: 8, // Required field, no default value, 0 is not legal argument
ExtraParams: map[string]string{"ef_search": "200"}, // Advanced params
}, {
Name: "column1",
IndexType: sdk.ProximaGraphIndex,
DataType: sdk.VectorFP16, // Index type is fp16, query could be fp32 for lack of language types
Dimension: 128,
ExtraParams: map[string]string{},
},
},
Repository: nil, // No repository attached
}
if err = client.CreateCollection(config); err != nil {
log.Fatal("Can't create collection.", err)
}
log.Print("Create collection succeed.")
}
示例 1.2: 创建一个带有两个正排列、单个向量索引列、以及Mysql Repo的集合
fun createCollctionWithRepoDemo(client *ProximaSearchClient) {
// Create collection with attached repository
config := &sdk.CollectionConfig{
CollectionName: "example_with_repo",
MaxDocsPerSegment: 0, // 0 means unlimited, which is equal max value of system
ForwardColumns: []string{"forward", "forward1"},
Columns: []sdk.ColumnIndex{{
Name: "column1",
IndexType: 0, // 0 means default index, which is sdk.ProximaGraphIndex
DataType: 0, // 0 means default, which is sdk.VectorFP32
Dimension: 512, // Required field, no default value, 0 is not legal argument
ExtraParams: map[string]string{"ef_search": "200"}, // Advanced params
},
},
Repository: &sdk.DatabaseRepository{
Repository: sdk.Repository{
Name: "mysql_repo",
Type: sdk.Database,
},
Connection: "mysql://host.com:8080/mysql_database", // JDBC connection uri
TableName: "table_name", // Table name
User: "root", // User name
Password: "root", // Password
},
}
if err = client.CreateCollection(config); err != nil {
log.Fatal("Can't create collection.", err)
}
log.Print("Create collection with attached mysql repository succeed.")
}
2.2. 获取集合配置信息
DescribeCollection(name string) (*CollectionInfo, error)
获取参数name指定的集合配置信息
参数说明:
- name: string指定集合名称
返回值:
- CollectionInfo: 指向CollectionInfo的指针,成功返回时该参数非nil, 失败时通过error参数判定失败原因
- error: 失败返回非nil
示例 2.1: 获取集合配置信息
fun describeCollectionDemo(client *ProximaSearchClient) {
// Retrieve collection named by 'example_with_repo'
info, err = client.DescribeCollection("example_with_repo")
if err != nil {
log.Fatal("Lost collection named by 'example_with_repo', which created before.", err)
}
log.Printf("Collection(With Repository): %+v\n", info)
// Delete collection
if err = client.DropCollection("example_with_repo"); err != nil {
log.Fatal("Failed to drop collection,", err)
}
log.Print("Drop collection succeed.")
}
2.3. 删除指定集合
DropCollection(name string) error
删除指定集合,集合名由参数name指定
参数说明:
- name: string指定集合名称
返回值:
- error: 失败返回非nil
示例 3.1: 删除集合
fun dropCollectionDemo(client *ProximaSearchClient) {
client.DropCollection("example_with_repo")
if err = client.CreateCollection(config); err != nil {
log.Fatal("Can't create collection.", err)
}
log.Print("Create collection with attached mysql repository succeed.")
}
2.4. 获取集合统计信息
StatCollection(string) (*CollectionStat, error)
获取参数指定的集合统计信息,执行成功返回指向CollectionStat的有效指针,失败返回error
参数说明:
- string: 指定集合名称
返回值:
- *CollectionStat: Collection的统计信息
- error: 失败返回非nil
示例 4.1: 获取集合统计信息
fun statCollectionDemo(client *ProximaSearchClient) {
stat, err := client.StatCollection("example")
if err != nil {
log.Fatal("Stat collection failed.", err)
}
log.Printf("Collection Stat: %+v", stat)
}
2.5. 获取集合列表
ListCollections(filters …ListCollectionFilter) ([]*CollectionInfo, error)
获取符合条件的集合列表,执行成功返回CollectionInfo的列表,失败返回error
参数说明:
- ListCollectionFilter: 过滤器对象,过滤器可采用生成器自动生成,可选的生成器如下: - ByRepo(repo string): 包含指定repo名称的Collection
返回值:
- []*CollectionInfo: CollectionInfo列表
- error: 失败返回非nil
示例 5.1: 获取集合列表
fun listCollectionsDemo(client *ProximaSearchClient) {
// List all collections
collections, err := client.ListCollections()
if err != nil {
log.Fatal("Can't retrieve collections from Proxima Server.", err)
}
log.Printf("Collections (%d): \n", len(collections))
for _, collection := range collections {
log.Printf("%+v\n", collection)
}
// List all collections by Repo
collections, err = client.ListCollections(sdk.ByRepo("repo"))
if err != nil {
log.Fatal("Can't retrieve collections from Proxima Server.", err)
}
log.Printf("Collections (%d): \n", len(collections))
for _, collection := range collections {
log.Printf("%+v\n", collection)
}
}
3. 文档管理
文档管理整合为一个通用接口Write, 通过接口参数描述所需的操作,接口定义如下:
Write(*WriteRequest) error
向BE中批量写入文档操作请求,执行成功后返回nil, 否则返回值error中描述了错误信息
参数说明:
- WriteRequest: 写入请求内容
// Row record
type Row struct {
// Primary key of row record
PrimaryKey uint64
// Operation type
OperationType
// Index column value list
IndexColumnValues []interface{}
// Forward column value list
ForwardColumnValues []interface{}
// Log Sequence Number context
*LsnContext
}
// RowMeta meta for row records
type RowMeta struct {
// Index column name list
IndexColumnNames []string
// Index column name list
ForwardColumnNames []string
}
// WriteRequest object, the parameter of ProximaBEClient.Write method
type WriteRequest struct {
// Name of collection
CollectionName string
// Meta header
Meta RowMeta
// Row record list
Rows []Row
// Request ID, Optional
RequestID string
// Magic number, Optional
MagicNumber uint64
}
Write API中根据传入参数的 Row.OperationType 判定当前数据是插入、删除、更新中的某种操作类型,可选的OperationType列表如下:
- **Insert: ** 新增文档
- Update: 更新文档
- Delete: 删除文档
返回值:
- error: 失败返回非nil
3.1. 文档插入
指定Row.OperationType为OPInsert可完成文档的插入操作
示例 1.1: 文档插入
fun insertDocumentDemo(client *ProximaSearchClient) {
rows := &sdk.WriteRequest{
CollectionName: "example",
Meta: sdk.RowMeta{
IndexColumnNames: []string{"column"},
ForwardColumnNames: []string{"forward", "forward1"},
},
Rows: []sdk.Row{
{
PrimaryKey: 0,
OperationType: sdk.Insert,
ForwardColumnValues: []interface{}{1, float32(1.1)},
IndexColumnValues: []interface{}{ // Data type should same with index created before
[]float32{1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0},
},
LsnContext: nil, // With empty context
},
},
RequestID: "", // Optional field
MagicNumber: 0, // Optional field
}
// Write rows to collection
err = client.Write(rows)
if err != nil {
log.Fatal("Insert data to collection failed.", err)
}
}
3.2. 文档更新
指定Row.OperationType为OPUpdate可完成文档的更新操作
示例 2.1:更新文档
fun updateDocumentDemo(client *ProximaSearchClient) {
rows := &sdk.WriteRequest{
CollectionName: "example",
Meta: sdk.RowMeta{
IndexColumnNames: []string{"column"},
ForwardColumnNames: []string{"forward", "forward1"},
},
Rows: []sdk.Row{
{
PrimaryKey: 0,
OperationType: sdk.Update,
ForwardColumnValues: []interface{}{2, float32(2.2)},
IndexColumnValues: []interface{}{ // Data type should same with index created before
[]float32{21.0, 22.0, 23.0, 24.0, 25.0, 26.0, 27.0, 28.0},
},
LsnContext: &sdk.LsnContext{ // With valid context
LSN: 0,
Context: "write context hear",
},
}},
RequestID: "", // Optional field
MagicNumber: 0, // Optional field
}
// Write rows to collection
err = client.Write(rows)
if err != nil {
log.Fatal("Insert data to collection failed.", err)
}
}
3.3. 文档删除
指定Row.OperationType为OPDelete可完成文档的删除操作
示例 3.1:删除文档
fun deleteDocumentDemo(client *ProximaSearchClient) {
rows := &sdk.WriteRequest{
CollectionName: "example",
Meta: sdk.RowMeta{
IndexColumnNames: []string{"column"},
ForwardColumnNames: []string{"forward", "forward1"},
},
Rows: []sdk.Row{
{
PrimaryKey: 0,
OperationType: sdk.Delete,
},
},
RequestID: "", // Optional field
MagicNumber: 0, // Optional field
}
// Write rows to collection
err = client.Write(rows)
if err != nil {
log.Fatal("Insert data to collection failed.", err)
}
}
3.4. 批量文档操作
请求中包含多行数据,并指定OperationType完成批量文档操作
示例 4.1:批量文档操作
fun batchDocumentOperationDemo(client *ProximaSearchClient) {
rows := &sdk.WriteRequest{
CollectionName: "example",
Meta: sdk.RowMeta{
IndexColumnNames: []string{"column"},
ForwardColumnNames: []string{"forward", "forward1"},
},
Rows: []sdk.Row{
{
PrimaryKey: 0,
OperationType: sdk.Insert,
ForwardColumnValues: []interface{}{1, float32(1.1)},
IndexColumnValues: []interface{}{ // Data type should same with index created before
[]float32{1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0},
},
LsnContext: nil, // With empty context
}, {
PrimaryKey: 2,
OperationType: sdk.Insert,
ForwardColumnValues: []interface{}{2, float32(2.2)},
IndexColumnValues: []interface{}{ // Data type should same with index created before
[]float32{21.0, 22.0, 23.0, 24.0, 25.0, 26.0, 27.0, 28.0},
},
LsnContext: &sdk.LsnContext{ // With valid context
LSN: 0,
Context: "write context hear",
},
}},
RequestID: "", // Optional field
MagicNumber: 0, // Optional field
}
// Write rows to collection
err = client.Write(rows)
if err != nil {
log.Fatal("Insert data to collection failed.", err)
}
}
4. 文档查询
4.1. 向量查询
Query(collection string, column string, features interface{}, opts …QueryOption) (*QueryResponse, error)
单次、批量向BE发起向量查询请求,执行成功返回QueryResponse的有效指针,失败返回error
参数说明:
- collection: string指定集合名称
- column: string指定列名
- features: 指定查询向量,该参数可以是切片、数组、或者二维矩阵(每行一个向量),向量中的原始数据类型支持int8/uint32/uint64/float32中的一种(由于语言限制,如果索引创建时数据类型配置为DTVectorFP16,请使用float32类型与BE交互,服务器端会自动进行类型转换)
- opts: QueryOption可选参数列表,可选的参数如下:
- WithTopK(int): 最近的邻居个数
- WithRadius(float32): 搜索半径,可选区间为0~1的浮点数,越大召回效果上升、性能下降,越小召回效果下降、性能上升。当请求中同时打开暴力匹配选项,则此参数无效。
- WithLinearSearch(): 暴力匹配选项,返回的为绝对topk结果(性能最低)
- WithDebugMode(): 调试模式,将详细搜索的各阶段统计数据返回(不建议生产环境中打开)
- WithParam(string, interface{}): 高级检索参数,可选配置项待发布
返回值:
- *QueryResponse: 最近邻的documents结果
- error: 失败返回非nil
示例 1.1: 单次向量查询
fun queryDemo(client *ProximaSearchClient) {
// Query one vector
resp, err := client.Query("example", "column", []float32{1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0}, sdk.WithTopK(10))
if err != nil {
log.Fatal("Query failed.", err)
}
log.Printf("Response: %+v\n", resp)
}
示例 1.2: 批量向量查询
fun batchQueryDemo(client *ProximaSearchClient) {
// Query with matrix
resp, err = client.Query("example", "column",
[][]float32{{1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0},
{1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0},
{1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0},
{1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0},
},
sdk.WithTopK(10),
sdk.WithDebugMode(), // Enable debug mode, do not recommend on product environments
sdk.WithRadius(1.5), // Search radius, no effect if sdk.WithLinearSearch enabled
sdk.WithLinearSearch(), // Enable linear search
sdk.WithParam("customize_param", 10),
sdk.WithParam("customize_param2", 1.0),
sdk.WithParam("customize_param3", "str"))
if err != nil {
log.Fatal("Query failed.", err)
}
log.Printf("Response: %+v\n", resp)
}
4.2. 主键查询
GetDocumentByKey(collection string, primaryKey uint64) (*Document, error)
通过文档主键获取文档,执行成功返回Document的有效指针,失败返回error
参数说明:
- collection: 集合名称
- primaryKey: 文档主键
返回值:
- *Document: 文档对象
- error: 失败返回非nil
示例 2.1: 根据文档主键获取文档内容
fun queryDocByPKDemo(client *ProximaSearchClient) {
// Retrieve document by primary key
doc, err := client.GetDocumentByKey("example", 0)
if err != nil {
log.Fatal("Failed to retrieve document from server.", err)
}
log.Printf("Document: %+v\n", doc)
}
6 - 案例教程
6.1 - 图片搜索
以图搜图是互联网应用中的常见功能,各大搜索引擎都提供了通过图片搜索相似图片的功能,另外“拍立淘”也是基于图片搜索实现的。本文介绍如何基于 Proxima Bilin Engine 来实现图片搜索功能,主要包括三个步骤:图片特征抽取、图片底库入库、在线检索。
图片特征抽取
为了实现图片搜索,需要从图片中抽取特征向量,用于建立向量索引并做 KNN 检索。一般是通过深度学习模型中的最后一层全连接层作为描述图片的特征。在这里,我们选用预训练好的 ResNet18 模型来抽取图片特征,其输入要求至少为 224*224 的 RGB 图片且已经做过标准化,输出特征为 512 维的float。
class FeatureExtractor(object):
def __init__(self):
self.model = models.resnet18(pretrained=True)
self.model.eval()
self.layer = self.model._modules.get("avgpool")
self.transform_pipeline = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
def get_feature(self, img):
t_img = Variable(self.transform_pipeline(img)).unsqueeze(0)
feat_vec = torch.zeros(512)
def copy_data(m, i, o):
feat_vec.copy_(o.data.squeeze())
h = self.layer.register_forward_hook(copy_data)
self.model(t_img)
h.remove()
return feat_vec.tolist()
fe = FeatureExtractor()
为了满足 ResNet18 的要求,我们定义了 transform_pipeline 来做图片 resize 和标准化。然后获取 avgpool 层,在 get_feature 中通过注册钩子来将特征数据拷贝到 feat_vec 中。
图片底库入库
我们以 Caltech 101 数据集为例,它包含101类的图片,每一类包括50张左右的图片。图片预先下载解压到 data/101_ObjectCategories 目录。
首先需要加载图片,由于 Caltech 101 数据集中部分图片是灰度图片,不满足,ResNet18 的要求,get_image_feature 中会做判断,必要时将其转换为 RGB 图片。
def get_image_feature(image_path):
i = Image.open(image_path)
if i.mode == 'L':
i = i.convert('RGB')
return fe.get_feature(i)
通过 get_feature_batch 函数来分批加载图片并抽取特征,一个 batch 内的图片特征会作为一次网络请求发送到 Proxima Bilin Engine 。
def get_feature_batch(batch_count=100):
result = []
dataset_dir = 'data/101_ObjectCategories'
p = pathlib.Path(dataset_dir)
for i in p.glob('**/*.jpg'):
image_path = str(i)
result.append((get_image_feature(image_path), image_path))
if len(result) >= batch_count:
yield result
result.clear()
if result:
yield result
使用 docker 容器启动 Proxima Bilin Engine 服务。
docker run -d --name proxima_be -p 16000:16000 -p 16001:16001 \
reg.docker.alibaba-inc.com/proxima/proxima-be
设置连接信息,创建 client。
from pyproximabe import *
HOST = '127.0.0.1'
GRPC_PORT = 16000
client = Client(HOST, GRPC_PORT)
创建 collection
collection_name = 'image_search'
index_column = IndexColumnParam(name='feature',
dimension=512,
data_type='VECTOR_FP32',
index_type=IndexType.PROXIMA_GRAPH_INDEX)
collection_config = CollectionConfig(collection_name=collection_name,
index_column_params=[index_column],
forward_column_names=['image_path'])
status = client.create_collection(collection_config)
if not status.ok():
print('create collection error:' + str(status))
print('Create collection successfully!')
在 Proxima Bilin Engine 中同时支持向量列和正排列。在上面的代码中,我们指定了创建一个向量列,它包含 512 维的 float 向量,使用 graph 索引;还指定了一个名为 image_path 的正排列,用于存储图片的路径。
图片入库
from itertools import count
pk_gen = count()
row_meta = WriteRequest.RowMeta(index_column_metas=[WriteRequest.IndexColumnMeta(name='feature',
data_type='VECTOR_FP32',
dimension=512)],
forward_column_names=['image_path'],
forward_column_types=[DataType.STRING])
for batch in get_feature_batch():
rows = []
for image_feature, image_path in batch:
rows.append(
WriteRequest.Row(primary_key=next(pk_gen),
operation_type=WriteRequest.OperationType.INSERT,
index_column_values=[image_feature],
forward_column_values=[image_path]))
write_request = WriteRequest(collection_name=collection_name,
rows=rows,
row_meta=row_meta)
status = client.write(write_request)
if not status.ok():
print('Fails, err=%s' % status)
break
print('.', end='')
print('write done')
Proxima Bilin Engine 要求向量有唯一整形标识,我们使用 itertools.count 来生成。上面的代码中,先创建了 row_meta,然后逐行添加向量,最后将 write_request 发送到服务端。
图片检索
def search_and_show(image_path):
query_vector = get_image_feature(image_path)
status, knn_res = client.query(collection_name,
column_name='feature',
features=[query_vector],
data_type='VECTOR_FP32',
topk=5)
assert status.ok()
query_img = Image.open(image_path)
fig_query, ax_query = plt.subplots(1,1, figsize=(5,5))
ax_query.imshow(query_img)
ax_query.axis('off')
ax_query.set_title("Query")
neighbors = knn_res.results[0]
doc_count = len(neighbors)
fig, ax = plt.subplots(1, doc_count, figsize=(10,10))
for i, doc in enumerate(neighbors):
doc_image_path = doc.forward_column_values['image_path']
ax[i].imshow(Image.open(doc_image_path))
ax[i].axis('off')
ax[i].set_title("Dist: %.3f" % doc.score)
search_and_show('data/101_ObjectCategories/cougar_face/image_0018.jpg')
search_and_show('data/101_ObjectCategories/butterfly/image_0001.jpg')
抽取到图片特征后,发送 query 请求到服务端,然后将结果以图片的方式展示出来。

需要说明的是,Proxima Bilin Engine 支持边插入边检索,不需要全部入库完即可提供检索服务。
7 - 常见问题
7.1 - 常见错误
1、ProximaBE 错误
1.1 基础错误
| 错误码 | 错误原因 |
|---|---|
| 1000 | 运行时错误 |
| 1001 | 逻辑错误 |
| 1002 | 状态错误 |
| 1003 | 载入配置文件错误 |
| 1004 | 配置文件错误 |
| 1005 | 参数无效 |
| 1006 | 未初始化 |
| 1007 | 打开文件错误 |
| 1008 | 读取数据错误 |
| 1009 | 写数据错误 |
| 1010 | 超出限制 |
| 1011 | 序列化错误 |
| 1012 | 反序列化错误 |
| 1013 | 开启服务器错误 |
| 1014 | 尝试访问已经停止的服务器 |
1.2 格式错误
| 错误码 | 错误原因 |
|---|---|
| 2000 | Collection Name 为空 |
| 2001 | Column Name 为空 |
| 2002 | Column 为空 |
| 2003 | Repository Table 为空 |
| 2004 | Repository Name 为空 |
| 2005 | User Name 为空 |
| 2006 | Password 为空 |
| 2007 | URI 无效 |
| 2008 | Collection Status 无效 |
| 2009 | Record 无效 |
| 2010 | Query 无效 |
| 2011 | Index Data Format 无效 |
| 2012 | Write Request 无效 |
| 2013 | Vector Format 无效 |
| 2014 | Repository Type 无效 |
| 2015 | Data Type 无效 |
| 2016 | Index Type 无效 |
| 2017 | Segment 无效 |
| 2018 | Revision 无效 |
| 2019 | Feature 无效 |
| 2020 | Schema 不匹配 |
| 2021 | Magic Number 不匹配 |
| 2022 | Index Column 不匹配 |
| 2023 | Dimension 不匹配 |
| 2024 | Data Type 不匹配 |
1.3 Meta 模块错误
| 错误码 | 错误原因 |
|---|---|
| 3000 | 尝试更新 Status Field (只读) |
| 3001 | 尝试更新 Revision Field (只读) |
| 3002 | 尝试更新 CollectionUID Field (只读) |
| 3003 | 尝试更新 IndexType Field (只读) |
| 3004 | 尝试更新 DataType Field (只读) |
| 3005 | 尝试更新 Parameters Filed (只读) |
| 3006 | 尝试更新 RepositoryType Field (只读) |
| 3007 | 尝试更新 ColumnName Field (只读) |
| 3008 | 每个 Segment 包含 0 个 Docs |
| 3009 | 不支持的链接类型 |
1.4 Index 模块错误
| 错误码 | 错误原因 |
|---|---|
| 4000 | Collection 重复 |
| 4001 | Key 重复 |
| 4002 | Collection 不存在 |
| 4003 | Column 不存在 |
| 4004 | Key 不存在 |
| 4005 | Collection 处于 Suspended 状态 |
| 4006 | Segment 丢失 |
| 4007 | Lsn Context 为空 |
| 4008 | 超过 Rate Limit |
1.5 Query 模块错误
| 错误码 | 错误原因 |
|---|---|
| 5000 | Segment 不可访问 |
| 5001 | Forward 列不匹配 |
| 5002 | Results 超过限制 |
| 5003 | Compute Queue 还没准备好 |
| 5004 | 任务调度出错 |
| 5005 | Collection 不可访问 |
| 5006 | Task 正在另外一个 coroutine 中运行 |
2. Repository 错误
2.1 基础错误
| 错误码 | 错误原因 |
|---|---|
| 1000 | 运行时错误 |
| 1001 | 逻辑错误 |
| 1003 | 载入配置文件错误 |
| 1004 | 配置文件错误 |
| 1005 | 参数无效 |
| 1006 | 未初始化 |
| 1007 | 打开文件错误 |
| 1010 | 超出限制 |
2.2 格式错误
| 错误码 | 错误原因 |
|---|---|
| 2020 | Schema 不匹配 |
| 2021 | Magic Number 不匹配 |
2.3 和 Agent 模块交互错误
| 错误码 | 错误原因 |
|---|---|
| 4000 | Collection 重复 |
| 4008 | 超过 Rate Limit |
2.4 MySQL repository 模块错误
| 错误码 | 错误原因 |
|---|---|
| 20000 | 链接 MySQL 失败 |
| 20001 | MySQL Table 无效 |
| 20002 | 执行 MySQL 命令错误 |
| 20003 | Table 中没有新数据 |
| 20004 | Row 数据无效 |
| 20005 | 不支持的 MySQL 版本 |
| 20006 | 执行 Command 失败 |
| 20007 | Binlog dump 失败 |
| 20008 | 没有新的 Binlog 数据 |
| 20009 | MySQL 结果无效 |
| 20010 | 不支持的 Binglog 格式 |
| 20011 | 获取 MySQL 结果失败 |
| 20012 | Binlog 处于 suspended 状态 |
| 20013 | MySQL Handler 未初始化 |
| 20014 | MySQL Handler 重复初始化 |
| 20015 | collection config 无效 |
| 20016 | Collection 不存在 |
| 20017 | RPC 失败 |
| 20018 | Collection 应当终止 |
| 20019 | URI 无效 |
| 20020 | 初始化 rpc channel 失败 |
| 20021 | MySQL Handler 无效 |
| 20022 | LSN context 无效 |
| 20023 | 没有更多的 Row 数据 |
| 20024 | Schema 发生了变化 |
| 20025 | Server 和 repository 的 version 不匹配 |
7.2 - 性能优化
7.3 - 部署问题
7.4 -
文档示例
这是一个目录
:depth: 2
这是一个注解
这是一个注解
:class: warning
这是一个警告
:class: tip
这是一个tip
这是一个下载示例
{download}我是文件名 <../data/proxima_se.conf>
这是一个数学公式
$$G = 1 - 2^{-1/a}$$
这也是一个数学公式
w_{t+1} = (1 + r_{t+1}) s(w_t) + y_{t+1}
这是一个可以缩放比例的图片
---
scale: 10
---
如何连接到指定位置
定义自己的tag,类似于自定义锚点,全局可用
(my_tag)= 我是my_tag对应的内容
{ref}对应到my_tag <my_tag>
常见错误:
特征向量:
集合管理:
现在可以自动生成标题锚点,锚点命名规则为,删除标点符号,空格转为'-',英文变为全小写,中文不变,下划线不变。
8 - 发行版本
8.1 -
9 - 性能测试
9.1 - 性能测试
1. 测试数据
5 份公开测试数据集分别从 ann-benchmarks 与 big-ann-benchmarks 中选取(为了测试不同数据量级下的性能表现,部分数据集只选取了其中一部分):
| dataset | dimension | type | distance | datasize |
|---|---|---|---|---|
| sift-128-euclidean | 128 | FP32 | Euclidean | 1,000,000 |
| gist-960-euclidean | 960 | FP32 | Euclidean | 1,000,000 |
| deep-image-96-angular | 96 | FP32 | Cosine | 10,000,000 |
| yandex-text-to-image | 200 | FP32 | InnerProduct | 100,000,000 |
| yandex-deep | 96 | FP32 | Euclidean | 1,000,000,000 |
2. 测试环境
- CPU:84 Core(Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz)
- 内存:464 GiB
- 磁盘:SSD
- GCC:8.3.0
- 指令集:Intel skylake-avx512
3. 测试说明
- 数据集分别采用 fp32/fp16/int8/int4 四类类型量化方式进行测试
- 索引构建采用 index_builder 工具来进行索引的构建
- 性能测试采用 bench_client 测试工具进行性能测试
- 构建采用图索引类型,相关参数为:max_neighbor_count=64,ef_search=200,ef_construction=500。例如如采用 Int8 量化,索引构建时使用的 schema 如下:
{
"collection_name": "yandex",
"index_column_params": [
{
"column_name": "feature",
"index_type": "IT_PROXIMA_GRAPH_INDEX",
"extra_params": [
{
"key": "quantize_type",
"value": "DT_VECTOR_INT8"
},
{
"key": "engine",
"value": "HNSW"
},
{
"key": "max_neighbor_count",
"value": "64"
}
],
"data_type": "DT_VECTOR_FP32",
"dimension": 96
}
]
}
3. 测试结果
3.1 sift-128-euclidean
3.1.1 构建信息
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| 索引大小 | 734M | 490M | 399M | 329M |
| 构建时间 | 66s | 57s | 50s | 48s |
3.1.2 查询性能
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| 1 并发 QPS/RT | 811/s 1132us | 922/s 980us | 982/s 932us | 1058/s 879us |
| 8 并发 QPS/RT | 6533/s 1212us | 7326/s 1084us | 7868/s 1011us | 8636/s 924us |
| 16 并发 QPS/RT | 12273/s 1339us | 14579/s 1165us | 15860/s 1077us | 15997/s 963us |
| 24 并发 QPS/RT | 15846/s 1454us | 18820/s 1261us | 20171/s 1140us | 22213/s 1029us |
| 32 并发 QPS/RT | 20671/s 1562us | 23389/s 1343us | 26223/s 1192us | 28353/s 1089us |
| 48 并发 QPS/RT | 24579/s 1898us | 29864/s 1547us | 34159/s 1364us | 38135/s 1231us |
| 64 并发 QPS/RT | 26829/s 2301us | 35575/s 1723us | 41072/s 1512us | 45778/s 1379us |
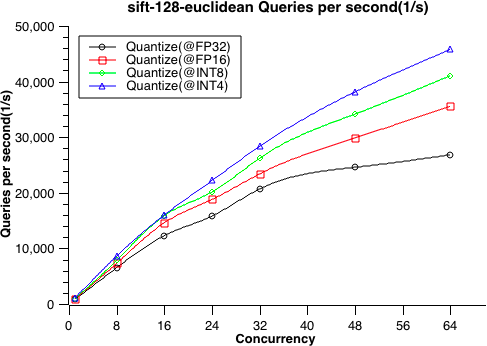
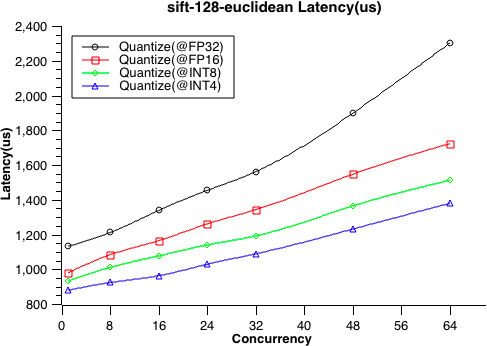
3.1.3 召回率
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| Top 1 召回率 | 99.99% | 99.99% | 96.33% | 61.46% |
| Top 10 召回率 | 99.94% | 99.94% | 97.25% | 71.88% |
| Top 20 召回率 | 99.89% | 99.89% | 97.54% | 74.48% |
| Top 30 召回率 | 99.84% | 99.84% | 97.68% | 75.76% |
| Top 40 召回率 | 99.79% | 99.79% | 97.82% | 76.58% |
| Top 50 召回率 | 99.74% | 99.74% | 97.85% | 77.28% |
| Top 60 召回率 | 99.68% | 99.68% | 97.88% | 77.82% |
| Top 70 召回率 | 99.61% | 99.61% | 97.90% | 78.21% |
| Top 80 召回率 | 99.54% | 99.54% | 97.91% | 78.58% |
| Top 90 召回率 | 99.47% | 99.46% | 97.91% | 78.90% |
| Top 100 召回率 | 99.39% | 99.39% | 97.92% | 79.19% |
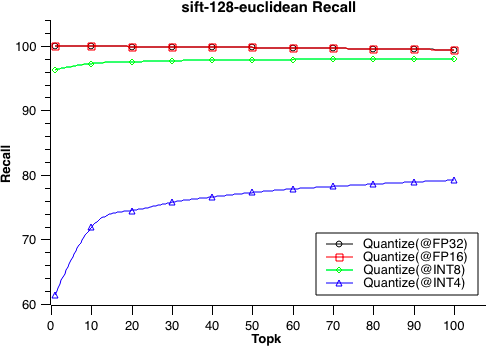
3.2 gist-960-euclidean
3.2.1 构建信息
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| 索引大小 | 3.8G | 2.0G | 1.2G | 686M |
| 构建时间 | 411s | 257s | 164s | 157s |
3.2.2 查询性能
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| 1 并发 QPS/RT | 221/s 4230us | 235/s 3978us | 391/s 2518us | 400/s 2398us |
| 8 并发 QPS/RT | 1722/s 4625us | 1868/s 4257us | 3051/s 2593us | 3204/s 2483us |
| 16 并发 QPS/RT | 2948/s 5179us | 3676/s 4410us | 5920/s 2694us | 6224/s 2550us |
| 24 并发 QPS/RT | 3835/s 6333us | 4876/s 4951us | 7975/s 3046us | 8689/s 2744us |
| 32 并发 QPS/RT | 4218/s 7652us | 6135/s 5242us | 10005/s 3179us | 11013/s 2870us |
| 48 并发 QPS/RT | 4308/s 11180us | 6935/s 6956us | 11896/s 4054us | 14549/s 3302us |
| 64 并发 QPS/RT | 4396/s 14622us | 7295/s 8817us | 12418/s 5077us | 17216/s 3761us |
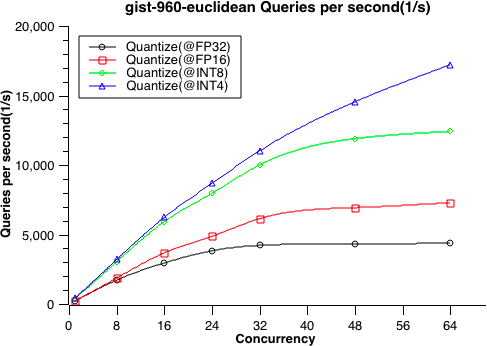
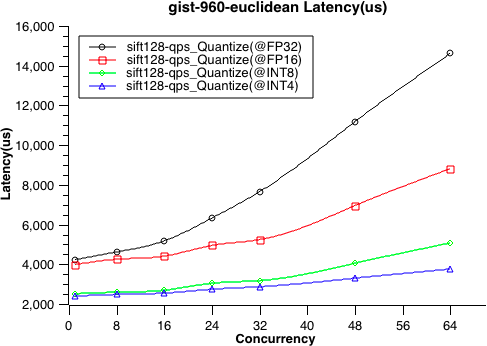
3.2.3 召回率
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| Top 1 召回率 | 99.68% | 99.66% | 96.06% | 55.64% |
| Top 10 召回率 | 99.43% | 99.34% | 96.76% | 66.81% |
| Top 20 召回率 | 99.19% | 99.10% | 96.96% | 69.53% |
| Top 30 召回率 | 98.98% | 98.91% | 97.00% | 70.96% |
| Top 40 召回率 | 98.78% | 98.70% | 97.02% | 71.91% |
| Top 50 召回率 | 98.57% | 98.50% | 96.94% | 72.48% |
| Top 60 召回率 | 98.38% | 98.32% | 96.86% | 73.02% |
| Top 70 召回率 | 98.18% | 98.12% | 96.76% | 73.47% |
| Top 80 召回率 | 97.98% | 97.92% | 96.68% | 73.82% |
| Top 90 召回率 | 97.79% | 97.73% | 96.57% | 74.11% |
| Top 100 召回率 | 97.63% | 97.57% | 96.48% | 74.40% |
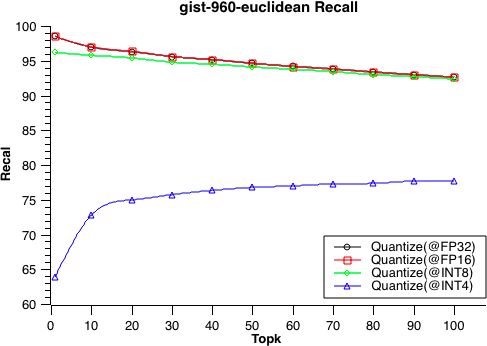
3.3 deep-image-96-angular
3.3.1 构建信息
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| 索引大小 | 6.3G | 4.6G | 4.0G | 3.3G |
| 构建时间 | 854s | 671s | 597s | 550s |
3.3.2 查询性能
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| 1 并发 QPS/RT | 646/s 1547us | 750/s 1333us | 729/s 1352us | 736/s 1345us |
| 8 并发 QPS/RT | 4910/s 1602us | 5891/s 1349us | 5756/s 1410us | 5817/s 1367us |
| 16 并发 QPS/RT | 9100/s 1696us | 11055/s 1408us | 10474/s 1462us | 11222/s 1449us |
| 24 并发 QPS/RT | 12915/s 1860us | 15766/s 1520us | 15379/s 1560us | 15679/s 1538us |
| 32 并发 QPS/RT | 15917/s 1998us | 19746/s 1611us | 19252/s 1659us | 19545/s 1625us |
| 48 并发 QPS/RT | 19863/s 2423us | 25792/s 1852us | 24753/s 1929us | 25421/s 1883us |
| 64 并发 QPS/RT | 22562/s 2825us | 30531/s 2101us | 29083/s 2184us | 30160/s 2107us |
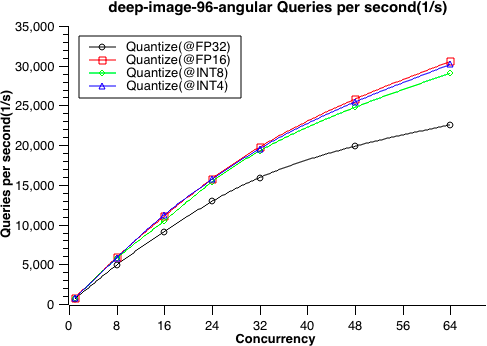
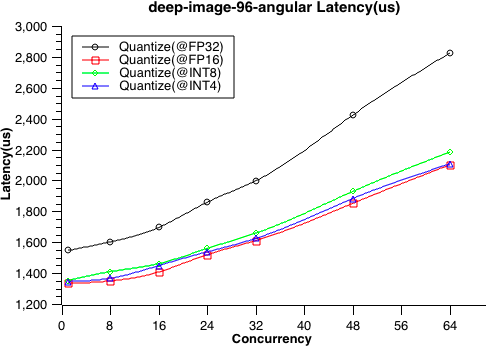
3.3.3 召回率
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| Top 1 召回率 | 99.68% | 99.66% | 96.06% | 55.64% |
| Top 10 召回率 | 99.43% | 99.34% | 96.76% | 66.81% |
| Top 20 召回率 | 99.19% | 99.10% | 96.96% | 69.53% |
| Top 30 召回率 | 98.98% | 98.91% | 97.00% | 70.96% |
| Top 40 召回率 | 98.78% | 98.70% | 97.02% | 71.91% |
| Top 50 召回率 | 98.57% | 98.50% | 96.94% | 72.48% |
| Top 60 召回率 | 98.38% | 98.32% | 96.86% | 73.02% |
| Top 70 召回率 | 98.18% | 98.12% | 96.76% | 73.47% |
| Top 80 召回率 | 97.98% | 97.92% | 96.68% | 73.82% |
| Top 90 召回率 | 97.79% | 97.73% | 96.57% | 74.11% |
| Top 100 召回率 | 97.63% | 97.57% | 96.48% | 74.40% |
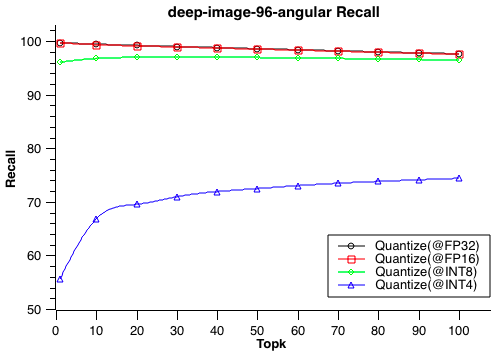
3.4 yandex-text-to-image
3.4.1 构建信息
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| 索引大小 | 100G | 64G | 46G | 37G |
| 构建时间 | 4h | 2.7h | 2.5h | 2.1h |
3.4.2 查询性能
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| 1 并发 QPS/RT | 500/s 1999us | 530/s 1942us | 565/s 1821us | 572/s 1765us |
| 8 并发 QPS/RT | 3839/s 2151us | 4175/s 1967us | 4251/s 1846us | 4366/s 1832us |
| 16 并发 QPS/RT | 6606/s 2275us | 7207/s 2067us | 8023/s 1915us | 8404/s 1881us |
| 24 并发 QPS/RT | 9746/s 2534us | 10172/s 2280us | 11246/s 2082us | 11887/s 2060us |
| 32 并发 QPS/RT | 11368/s 2847us | 13136/s 2375us | 14709/s 2189us | 15081/s 2140us |
| 48 并发 QPS/RT | 12888/s 3708us | 16914/s 2894us | 18466/s 2591us | 19356/s 2467us |
| 64 并发 QPS/RT | 13523/s 4711us | 18051/s 3517us | 20718/s 3018us | 22637/s 2823us |
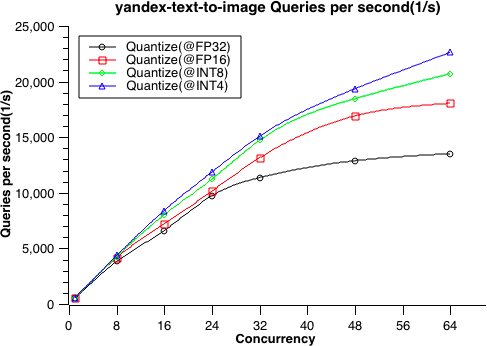
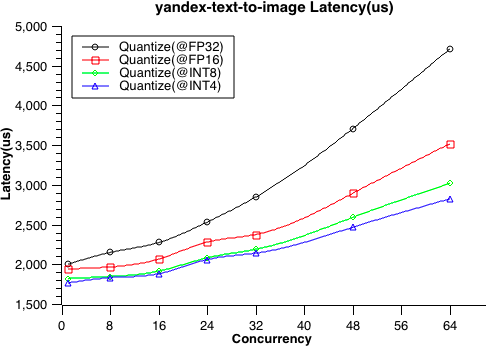
3.4.3 召回率
| 量化类型 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|
| Top 1 召回率 | 99.80% | 99.75% | 98.07% | 69.50% |
| Top 10 召回率 | 99.80% | 99.69% | 97.78% | 74.08% |
| Top 20 召回率 | 99.72% | 99.59% | 97.73% | 75.07% |
| Top 30 召回率 | 99.61% | 99.48% | 97.91% | 75.83% |
| Top 40 召回率 | 99.52% | 99.39% | 97.84% | 76.58% |
| Top 50 召回率 | 99.44% | 99.31% | 97.92% | 77.11% |
| Top 60 召回率 | 99.35% | 99.22% | 97.90% | 77.56% |
| Top 70 召回率 | 99.26% | 99.13% | 97.87% | 77.95% |
| Top 80 召回率 | 99.15% | 99.03% | 97.85% | 78.31% |
| Top 90 召回率 | 99.08% | 98.96% | 97.85% | 78.62% |
| Top 100 召回率 | 98.99% | 98.87% | 97.77% | 78.83% |

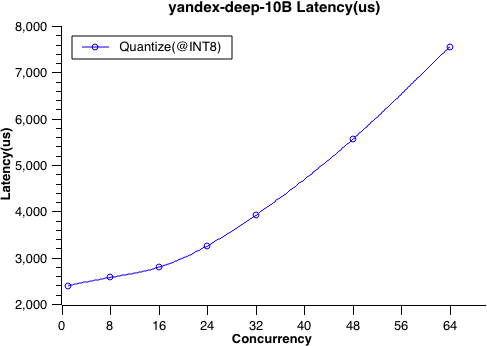
3.5.3 召回率
| 量化类型 | INT8 |
|---|---|
| Top 1 召回率 | 92.07% |
| Top 10 召回率 | 93.11% |
| Top 20 召回率 | 93.05% |
| Top 30 召回率 | 92.88% |
| Top 40 召回率 | 92.59% |
| Top 50 召回率 | 92.27% |
| Top 60 召回率 | 91.96% |
| Top 70 召回率 | 91.63% |
| Top 80 召回率 | 91.30% |
| Top 90 召回率 | 91.00% |
| Top 100 召回率 | 90.64% |